Aktywne Wpisy

WielkiNos +337
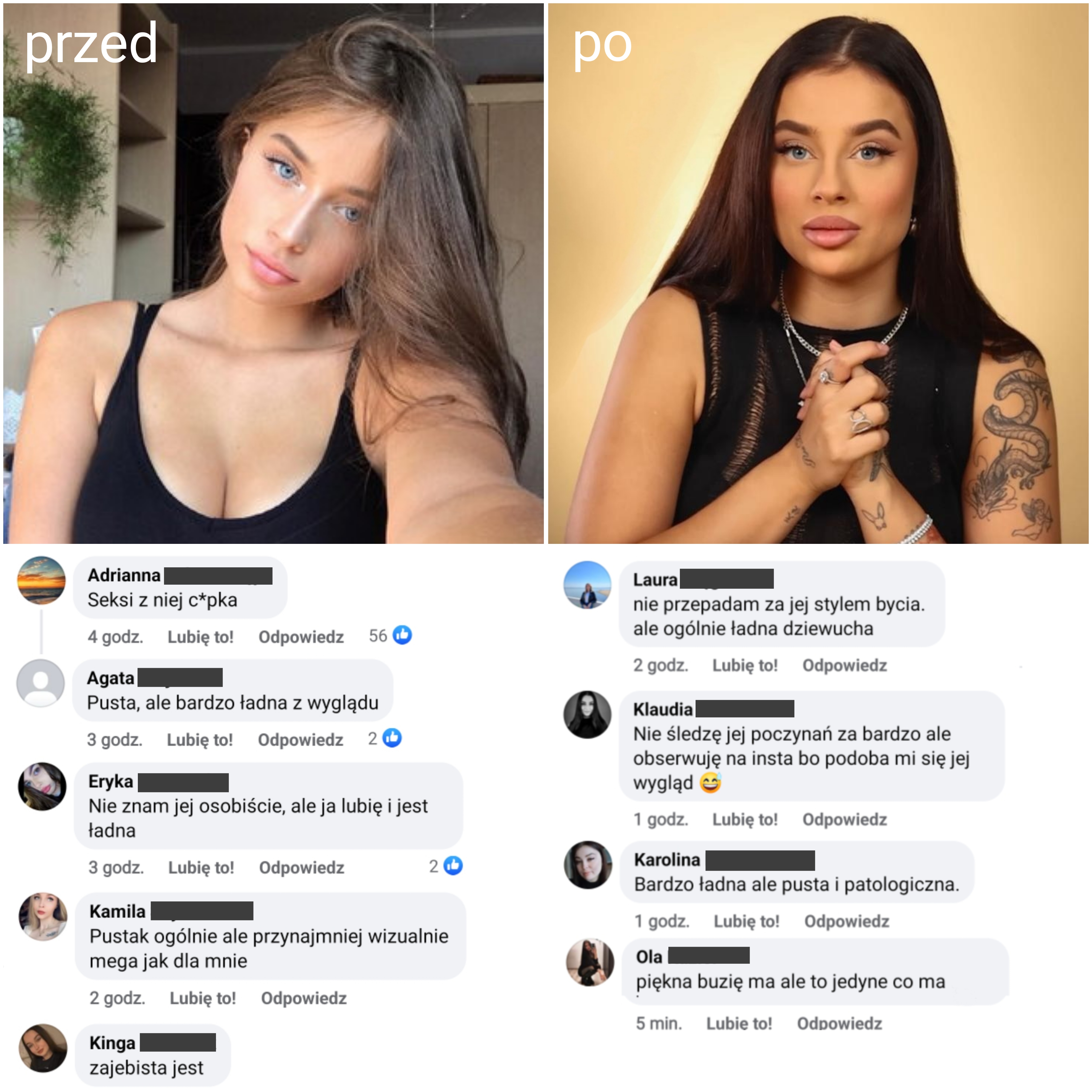
Jeśli taki sztuczny wygląd i zmiana z naturalnej, atrakcyjnej kobiety w instagramowy, wytatuowany klon z brwiami odrysowanymi od szablonu i napompowanymi ustami to dla współczesnych kobiet wzór do naśladowania i prawdziwe piękno to nie mam pytań. Mi się przykro na to patrzy.
#fagata #sztucznapani #logikarozowychpaskow
#fagata #sztucznapani #logikarozowychpaskow
źródło: temp_file351930140322580082
Pobierz
badreligion66 +529

źródło: temp_file1843939278618466679
Pobierz



{kind=link}
{kind=link}
[torch/tf] | cpu | gpu
local | 47/28 | x /18
colab | 42/52 | 1.1/1.0
[torch/tf] | cpu | gpu
local | 50/25 | x /16
colab | 35/39 | 2.5/1.0
Z jakiegoś powodu na CPU lokalnie tf działa znacznie szybciej niż torch oraz CPU na colabie, na colabie delikatna przewaga jest na korzyść torcha. Najlepsze wyniki osiąga tf na GPU, torch wydaje się znacznie odstawać. Stare GPU AMD potrafi trochę pomóc ale ograniczenie jedynie do połowy zasobów jest smutne. Wadą treningu na AMD jest jednak wymuszenie stosowania starszej wersji Kerasa i potrzeba stworzenia oddzielnego środowiska do normalnego użytkowania tf na CPU.
#programowanie #python #datascience #machinelearning