Aktywne Wpisy

IntruderXXL +64
Nabite 140 kilogramów, w upper, bo nóżki bociana. Dawno nie wrzucałem nic, cóż... szybkie życie porywa. Od lutego lecę grubo, jak to ja, ekstremalnie i po bandzie.
Ale jak widać moje treningi na 50-60%, brak diety, brak snu, i ciągłe imprezy nie przeszkadzają żeby robić formę :P Cóż sportowcem nigdy nie byłem, ja to wariat pasjonat który uwielbia trenować dla siebie.
Jeszcze trochę lecenia zostaje, ale czas wrócić do rozwoju, do większych
Ale jak widać moje treningi na 50-60%, brak diety, brak snu, i ciągłe imprezy nie przeszkadzają żeby robić formę :P Cóż sportowcem nigdy nie byłem, ja to wariat pasjonat który uwielbia trenować dla siebie.
Jeszcze trochę lecenia zostaje, ale czas wrócić do rozwoju, do większych

źródło: XXL
Pobierz{kind=link}

czteroch +123
Liczba, z której najczęściej żartuje się w krajach europejskich.
#mapporn
#mapporn
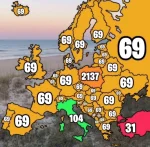
źródło: temp_file790575449658597413
Pobierz{kind=link}
Aktywne Znaleziska





[TimeStamp], [Open], [Close], [High], [Low], [Volume], [BaseVolume]8/14/2015 9:06:00 AM,0.00690000,0.00690000,0.00690000,0.00690000,1.34611713,0.00928820
Jak to wczytac w #r #rstudio ?
#statystyka #datascience
read_delim(path, sep = ',', trim_ws = TRUE, col_names = TRUE)@scyth: super, dzieki
W odróżnieniu od Pythona R jest językiem funkcyjnym, a nie stricte obiektowym, metody należą tu do funkcji, i to może na początek razić. Na szczęście pipe operator
%>%z tidyverse/dplyr daje namiastkę OOP. Co prawda obiekty dalej nie są