Aktywne Wpisy

lubieczipsy_ +64
Przeprowadziłem się do nowego mieszkania i jest jakaś grupa na fb sąsiedzka.
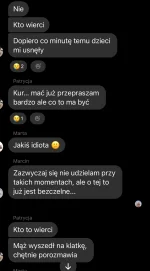
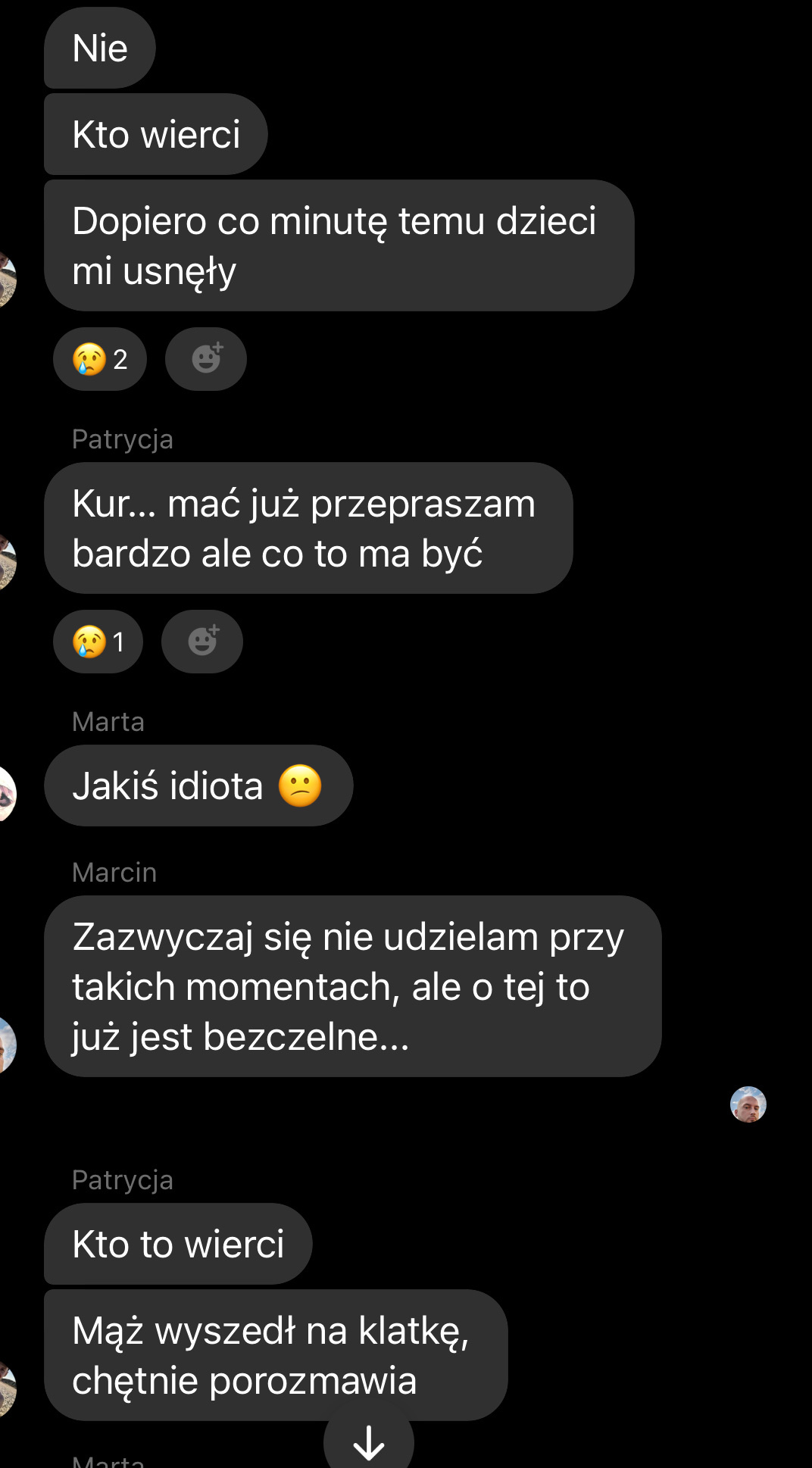
Chlop pewnie cały tydzień zapracowany i musiał wywiercić dziurę w ścianie bo wcześniej nie miał czasu a tu jakieś pretensje bo jest 20:30. Co o tym myślicie?
Reszta zdj w komentarzu.
#mieszkanie #madki #patodeweloperka
Chlop pewnie cały tydzień zapracowany i musiał wywiercić dziurę w ścianie bo wcześniej nie miał czasu a tu jakieś pretensje bo jest 20:30. Co o tym myślicie?
Reszta zdj w komentarzu.
#mieszkanie #madki #patodeweloperka
Krulsalomon +46





{kind=link}
{kind=link}
Źródło
#internet #internetexplorer #html