Aktywne Wpisy

nobody_here +129
najlepiej wydane 170 zł ostatnio xd #konsole #retrogaming

źródło: 1000008630
Pobierz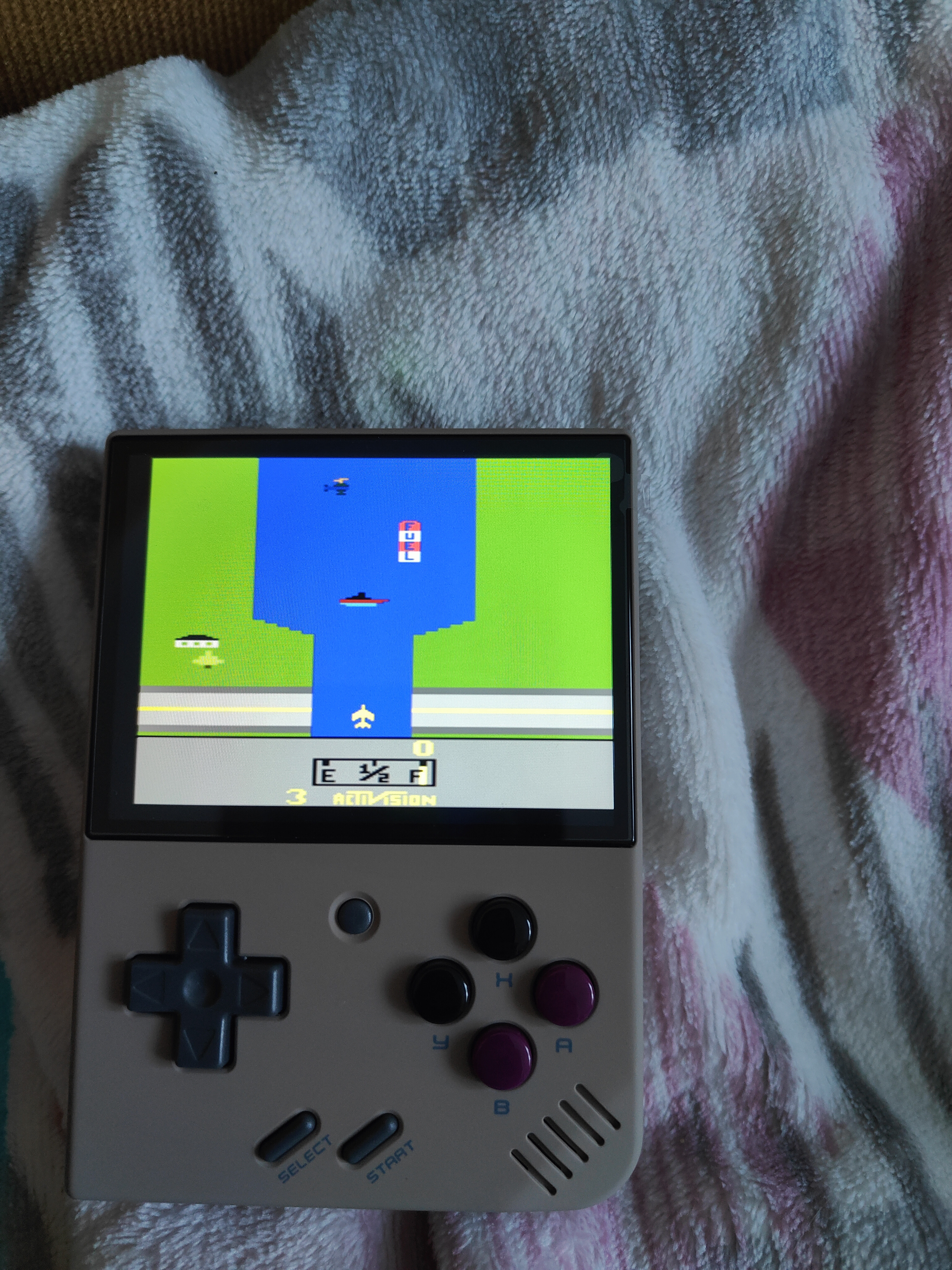{kind=link}
Dzonsin +6
#pracbaza #pracait #inwestycje #praca #warszawa #kapital
Mam do Was pytanie oraz chce zaczerpnąć inspiracji jak rozwiązać nasz (mój i żony) problem.
Kariera:
Wraz z żoną ukończyliśmy studia informatyczne z tytułem magistra/inżyniera. Podczas studiów znaleźliśmy staż (ja Python Developer, żona w analityce biznesowej.
Niedługo stuknie nam 30 lat, ja już Senior w przyjaznym korpo (na pracę nie narzekam 3x zdalnie 2x stacjonarnie). Łącznie ok. 20-30h przepracowane w ciągu tygodnia, czasami jak więcej pracy
Mam do Was pytanie oraz chce zaczerpnąć inspiracji jak rozwiązać nasz (mój i żony) problem.
Kariera:
Wraz z żoną ukończyliśmy studia informatyczne z tytułem magistra/inżyniera. Podczas studiów znaleźliśmy staż (ja Python Developer, żona w analityce biznesowej.
Niedługo stuknie nam 30 lat, ja już Senior w przyjaznym korpo (na pracę nie narzekam 3x zdalnie 2x stacjonarnie). Łącznie ok. 20-30h przepracowane w ciągu tygodnia, czasami jak więcej pracy
Aktywne Znaleziska





Owy katalog jest na bieżąco aktualizowany, więc jeżeli chciałbym zsynchronizować się z katalogiem, to jest problem... bo nie bardzo wiem, który rekord porównać z którym rekordem w mojej bazie.
Liczenie sumy kontrolnej jest bez sensu, gdyż aktualizacja jednego pola modyfikowałaby ową sumę i zamiast zaktualizować stary rekord, stworzyłbym nowy, bardzo podobny.
Jak wyjść z takiej sytuacji?
#programowanie #bazydanych
Komentarz usunięty przez autora
Pracuje z plikacjami ktore pobieraja dane z kilku zrodel i po przetworzeniu zapisuja je do bazy - jako nowy rekord lub jako aktualizacje. Ale w specyfikacji cala logika biznesowa jest dokladnie opisana - co, jak, na jakiej podstawie etc.
@msq: nie mam pojęcia jak to u nich działa. Może faktycznie po swojej stronie oni mają ID, jednak faktem jest to, że go nie podają na zewnątrz.
@noisy: To zostaje Ci tylko przeladowywanie calej bazy.
A po czym ty wybierasz te dane?
Zacząłem się zastanawiać, czy nie zrobić czegoś takiego, że dziele dane z otrzymanego rekordu an 3-4 grupy. Dla każdej z tej grup liczę sumę kontrolną. Każdą sumę bym sobie zapisał. Owe sumy były by używane tylko do aktualizacji. Każdy rekord o niepowtarzalnych sumach dostałby przydzielone id przez bazę.
Przy aktualizacji sprawdzałbym, czy istnieje jakiś inny rekord, który posiada co najmniej dwie takie
@anonim1133: wyszukiwanie jest tekstowe. Czyli na dane słowo otrzymuję listę wpisów, które gdzieś te słowo posiadają. Osobnym problemem jest w ogóle odpytanie tego katalogu, by dostać wszystkie wpisy....
Dziwne.