Aktywne Wpisy

Djuk94 +129
Dlaczego ostatnio tak wszyscy eksperci nawołują, że będzie wojna, podczas gdy Rosja ma jak na razie problem z zajmowaniem miast na Ukrainie? Widzę, że ten sam spektakl, co z ekspertami od AI, którzy rok temu nawoływali, że za pół roku, a może nawet w ciągu paru miesięcy czeka nas wielki przełom, świat nie do poznania! I ugasło. Nie sądzę, że wojna z Rosją nam grozi w tym dziesięcioleciu po tym, co pokazują

kantek007 +182
Polacy najwieksi niewolnicy #praca

źródło: GI3eK2yWYAAEZJ9
Pobierz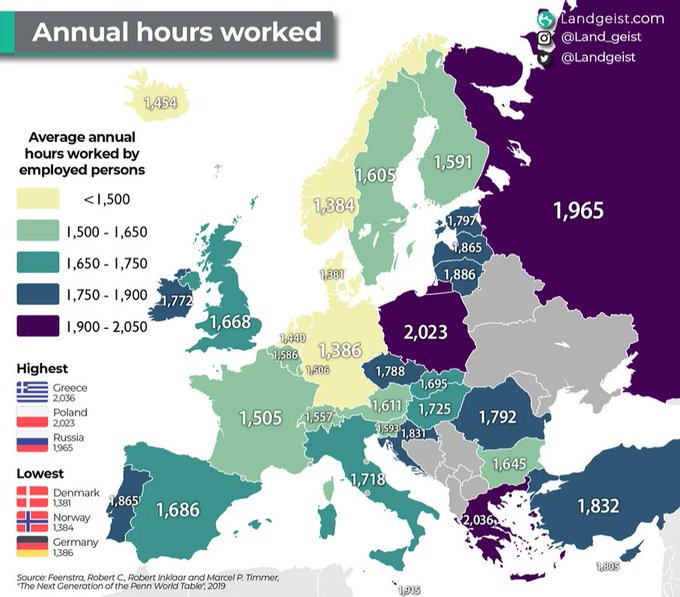{kind=link}
Aktywne Znaleziska




#programowanie #python #naukaprogramowania