Aktywne Wpisy

wfyokyga +35
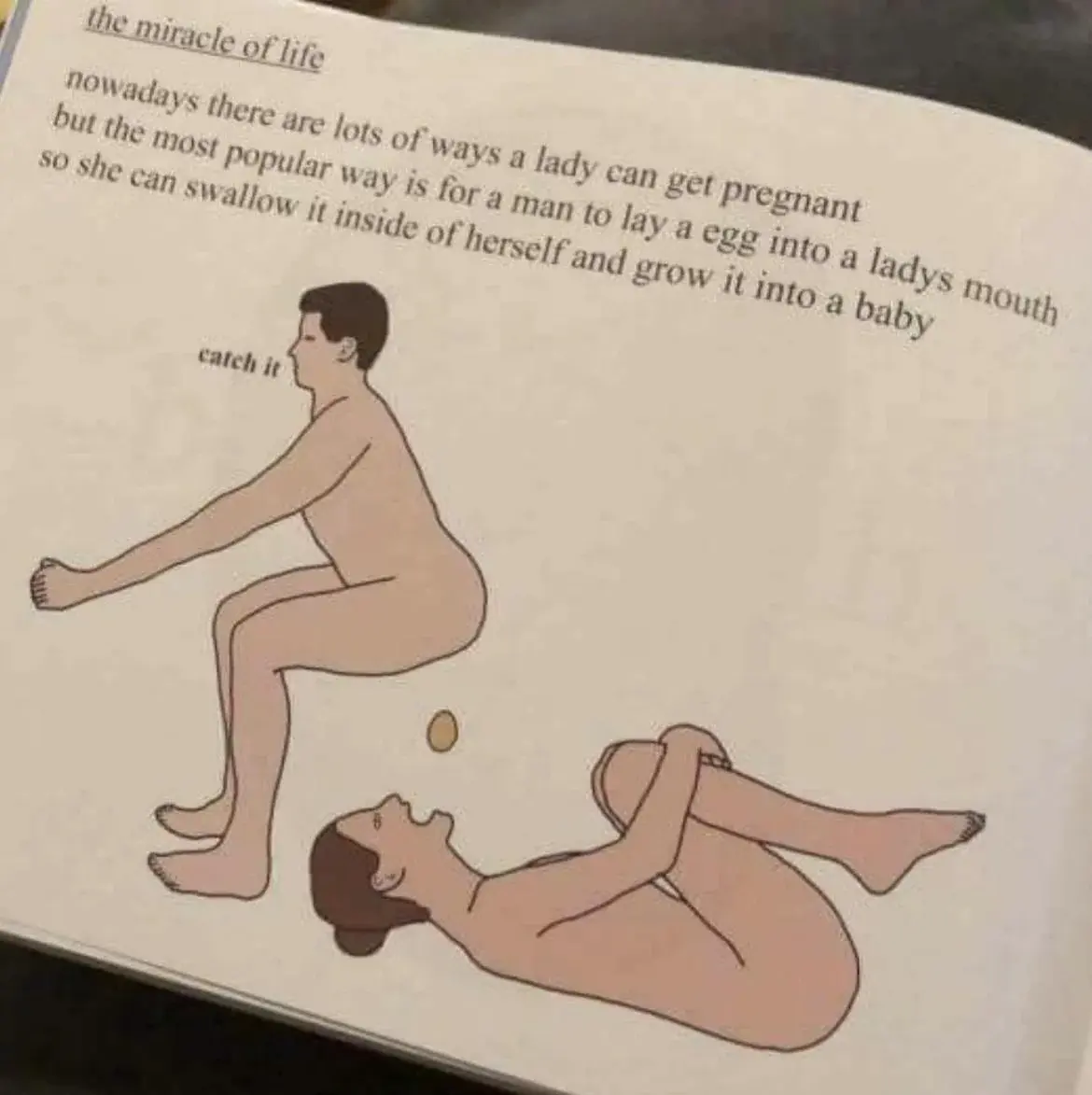
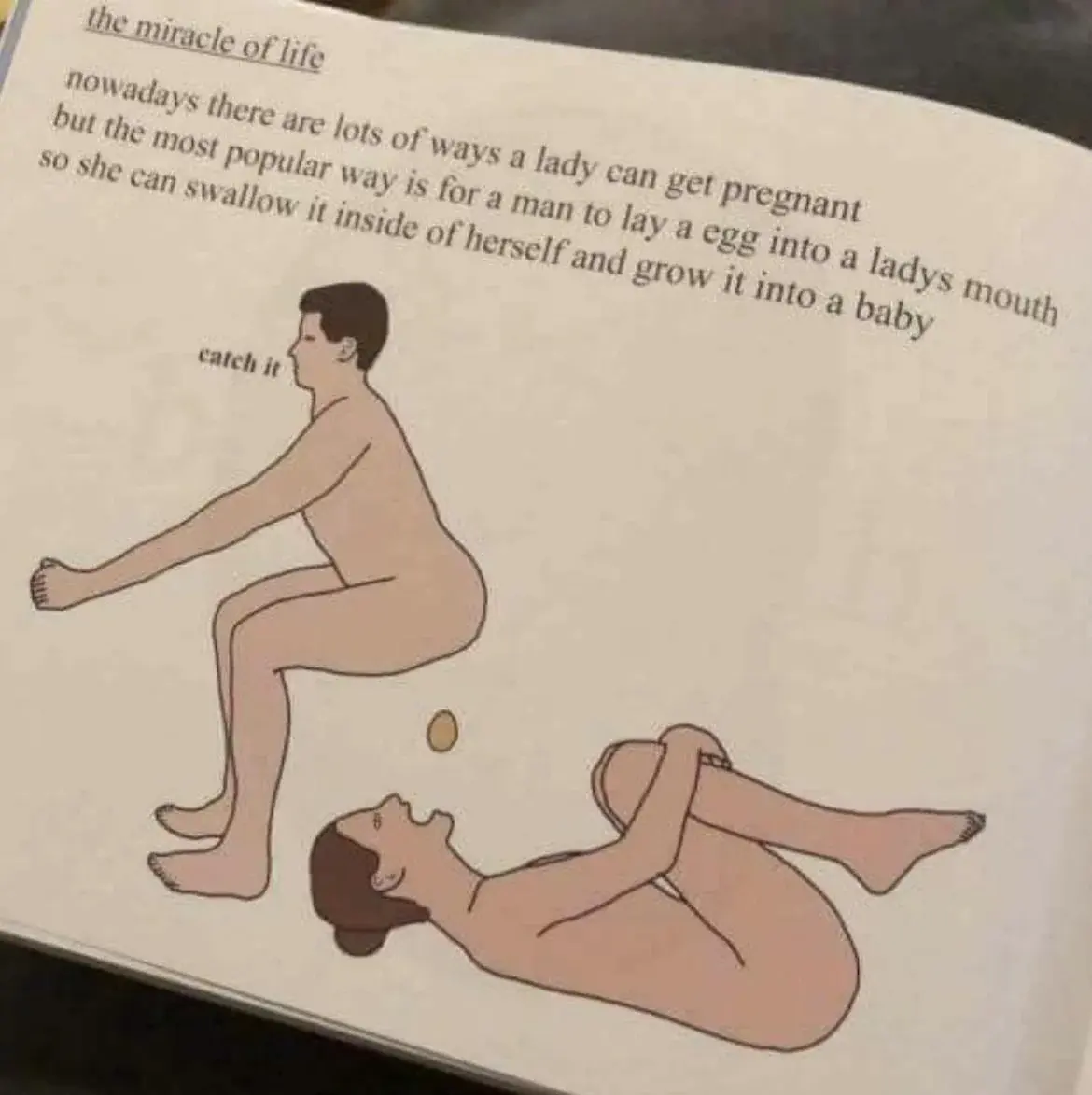
Dzień dobry
źródło: temp_file1738553455121218557
Pobierz
CoDwa +1
Czy wypijanie codziennie 4-5 piwek pod wieczór to alkoholizm? Tzn nie do końca codziennie bo czasem robię sobie przerwy kilka dni, tydzień, 2 tygodnie. Nigdy nie piję rano ani przed 18
#alkoholizm #pytanie #pytaniedoeksperta
#alkoholizm #pytanie #pytaniedoeksperta





{kind=link}
Mam dlugi vector danych. Dziele go na kawalki i procesuje na osobnym korzystajac z
std::launch::async. Nie ma data dependencies. Jezeli kawalkow jest 1000 to 1000 threadow zostanie odpalonych. Pytanie, czy moge zaufac schedulerowi, ze to jakos ogarnie, czy lepiej napisac semafor taki jak tu: https://www.reddit.com/r/cpp_questions/comments/5ih1g8/how_do_i_limit_the_number_of_threads_used_by/ i ograniczyc liczbe watkow do liczny rdzeni cpu? Martwie sie o to ze wzgledu na context switching.https://www.boost.org/doc/libs/1_66_0/doc/html/boost_asio/reference/thread_pool/thread_pool.html
ogólny tutorial boost::asio: https://www.gamedev.net/blogs/entry/2249317-a-guide-to-getting-started-with-boostasio/
@KrzaQ2: jest w standardwej bibliotece jakies standardowe, proste rozwiazanie out of the box do tego, czy musze sam pisac? Problem wydaje mi sie na tyle typowy, ze spodziewalbym sie jakiegos gotowego rozwiazania
Niestety, ale obecnie algorytmy w C++17 są mocno ograniczone i trudno określić liczbę wątków lub chunk size.
for (...) {jobs.push_back(
std::async(
std::launch::async,