Aktywne Wpisy

WielkiNos +75
Menel94 +2
Ile waszym zdaniem powinna realnie kosztować całościowo usługa (robocizna plus materiały zapewniał warsztat):
wymiana oleju, płynu hamulcowego, płynu chłodniczego, kompletu filtrów (bez filtra paliwa bo nie ma)?
Samochód to renault clio z 2010 roku benzyna 1.6, piszcie tu swoje wyceny a potem wszystkich zawołam i napiszę ile mi zaśpiewali, zastanawiam się czy mnie #!$%@? czy teraz rzeczywiście takie drogie usługi motoryzacyjne. Oczywiście nie korzystałem z jakiegoś autoryzowanego serwisu renault czy coś ;p
wymiana oleju, płynu hamulcowego, płynu chłodniczego, kompletu filtrów (bez filtra paliwa bo nie ma)?
Samochód to renault clio z 2010 roku benzyna 1.6, piszcie tu swoje wyceny a potem wszystkich zawołam i napiszę ile mi zaśpiewali, zastanawiam się czy mnie #!$%@? czy teraz rzeczywiście takie drogie usługi motoryzacyjne. Oczywiście nie korzystałem z jakiegoś autoryzowanego serwisu renault czy coś ;p





{kind=link}
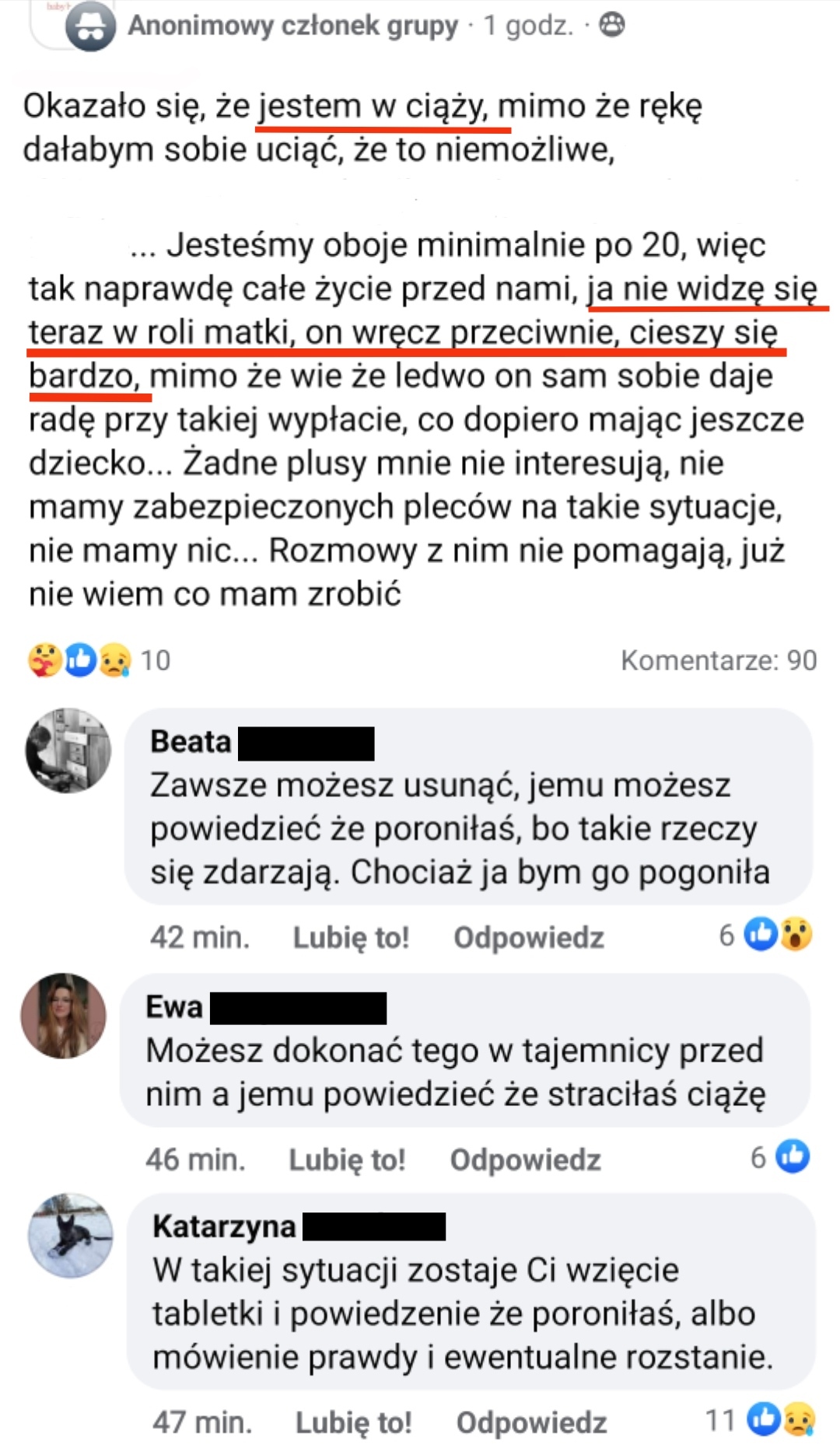
Do tego napisałem z pomocą kodu z neta sieć neuronową dwuwarstwową MLP z pomocą numpy, gdzie warstwa ukryta ma regulowaną długość, a warstwa wyjściowa to wektor klasyfikowanych owoców. Dla wektora wejściowego o długości np 4 sieć działa bez problemu, jednak kiedy daje na wejście mój wektor obrazów, sieć działa tylko do 10 neuronów w warstwie ukrytej, ze względu na duże tablice wag synaps dla większej ilości neuronów oraz ma overflow na funkcji aktywacji, czyli krótko mówiąc lipa.
Czy jest tu może ktoś kto rozwiązywał podobny problem klasyfikacji obiektów na podstawie obrazów lub jakiś osoba orientująca się w temacie? Możliwe, że sposób opisu deskryptorów mógłbym zrobić w inny sposób, jednak ten wydał mi się dobry, minusem jest jedynie długość wektora, nie modyfikowałem wielkości liczb wektora wejściowego.
Liczę na jakieś podpowiedzi co do możliwości rozwiązania problemu, jednak nie interesuje mnie korzystanie z kernela czy scilaba, moim założeniem jest by zbudować sieć bazującą jedynie na własnych obliczeniach. Miejcie też wyrozumiałość do mojej nieznajomości tematu, ale od czegoś trzeba zacząć ;)
#programowanie #siecineuronowe #machinelearning
Nie za bardzo rozumiem, wymiar Twojej warstwy wejściowej zależy od ilości przykładowych zdjęć?
Zgaduję że jako że Twoja ukryta wartstwa to zwykła warstwa fully connected i w takim wypadku używasz jakiegoś dekodera czy tam feature extractora który opisuje obraz w postaci n-elementowego wektora i wtedy wejście sieci ma n wymiarów.
No i kiedy Ci się to wywala, w trakcie treningu czy predykcji?
Czy w
Jeśli chodzi o wektor wejściowy to jest to tablica Xn obrazów, gdzie każdy xi to wynik opisu deskryptora obrazu.
Na wejście sieci podaje cały zestaw swoich danych X i Y i uruchamiam pętlę o długości wektora Xn, w której trenuje kolejne epoki(w moim rozumieniu zestawy danych* moge się mylić) za pomocą wstecznej propagacji błędów.
Każda taka epoka wykonuje predykcje na podstawie xi, i z
@mojemirabelki: (。◕‿‿◕。)
Co do samego treningu jedna epoka to jest przedział w którym przez propagację przeliczymy wszystkie przykłady.
No i przykłady takie przeliczamy często w grupach, tzw batchach.
W skocie chodzi o to że jakbyś updatował wagi dla
Wybaczcie ale programowanie tego bez podstaw teoretycznych to trochę bez sensu
Epoka czy batch size czy regularyzacja to tak samo podstawowe terminy jak klasa w C++ czy innej Javie
@darkelf: Tak to wszystko może być bez sensu, niech się chłopak uczy jak chce, w taki sposób więcej zrozumie
@mojemirabelki: ML wygląda tak, że tworzysz model, uczysz go, sprawdzasz jak działa, zmieniasz architekturę, czyli np. liczbę neuronów, robisz to wiele razy, nie zgadniesz tej liczby, nikt Ci nie jej poda