#databricks #programowanie #udemy Sprawdzal ktos kursy Udemy do Databricks Professional Data Engineer i bylby w stanie polecic czy raczej slabej jakosci i PartnerAcademy wystarczy?
Wszystko
Najnowsze
Archiwum
Dorydy

Hey #scala
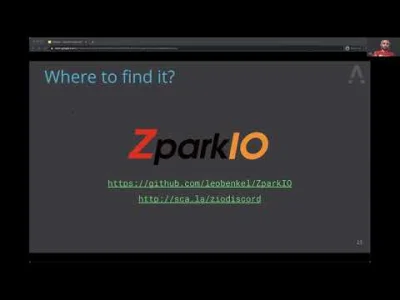
Macie może jakieś dobre tutoriale, dokumentację odnośnie implementacji ZIO ze #spark ?
Na głównym repo ziverge od zio-spark nie mogę dużo znaleźć, a znowu film Pana Leo Benkela bardzo mnie zaciekawił i chciałbym trochę bardziej zgłębić temat:
#apachespark #databricks
Macie może jakieś dobre tutoriale, dokumentację odnośnie implementacji ZIO ze #spark ?
Na głównym repo ziverge od zio-spark nie mogę dużo znaleźć, a znowu film Pana Leo Benkela bardzo mnie zaciekawił i chciałbym trochę bardziej zgłębić temat:
#apachespark #databricks
Słuchajcie mam zagadkę. Z zakresu troche fanaberii i sci-fi.
Raczej mniej istotne tło problemu:
Tworzę sobie Wheela w #pythonie i do pełnego wykorzystania tej libki, którą zbuduje jest potrzebna inna libka udostępniana jako plik .JAR.
Lokalnie jak sobie z tym pracuje i odpalam kod w ramach mojego develpmentu na sparku to mam zwyczajnie załączony ten JAR w odpowiedniej lokalizacji i wskazuje go podczas budowania SparkSession. Tak jak na uproszczonym przykłądzie poniżej:
Raczej mniej istotne tło problemu:
Tworzę sobie Wheela w #pythonie i do pełnego wykorzystania tej libki, którą zbuduje jest potrzebna inna libka udostępniana jako plik .JAR.
Lokalnie jak sobie z tym pracuje i odpalam kod w ramach mojego develpmentu na sparku to mam zwyczajnie załączony ten JAR w odpowiedniej lokalizacji i wskazuje go podczas budowania SparkSession. Tak jak na uproszczonym przykłądzie poniżej:

@inny_89 init scriptem
@Kura_Wasylisa zapomniałem dać znać, że
@ProfesorBigos naprowadził mnie na rozwiązanie. Wystarczy dołączyć zależności do wheela, razem zbudować i je później wykorzystać. Dziękuję Panie Profesorze!
@ProfesorBigos naprowadził mnie na rozwiązanie. Wystarczy dołączyć zależności do wheela, razem zbudować i je później wykorzystać. Dziękuję Panie Profesorze!
Panowie,
Jest ktoś na sali komu udało się skonfigurować databricks-connect i pracuje z lokalnego IDE na #databricks?
Albo może używa tego projektu: https://github.com/bricksflow/bricksflow ?
Walcze z tym gównem już stanowczo za długo i jesli jest ktoś kto by podpowiedział jak udało mu się to skonfigurowac to byłbym super
Jest ktoś na sali komu udało się skonfigurować databricks-connect i pracuje z lokalnego IDE na #databricks?
Albo może używa tego projektu: https://github.com/bricksflow/bricksflow ?
Walcze z tym gównem już stanowczo za długo i jesli jest ktoś kto by podpowiedział jak udało mu się to skonfigurowac to byłbym super
Panowie drodzy,
Potrzebuję drobnego wsparcia i dobrej rady z zakresu #databricks #scala #databricks-connect
Już opisuje problem:
Chcę zbudować JAR z projektu sbt utworzonego lokalnie przy wykorzystaniu databricks-connect i później uruchomić ten JAR w jobie na clustrze #azure Databricks.
Chciałem z poziomu lokalnego projektu, który sobie pisze w Intellij dobrać się do komponentu KeyVault na moim koncie Azure, żeby przeczytać Secrets tam
Potrzebuję drobnego wsparcia i dobrej rady z zakresu #databricks #scala #databricks-connect
Już opisuje problem:
Chcę zbudować JAR z projektu sbt utworzonego lokalnie przy wykorzystaniu databricks-connect i później uruchomić ten JAR w jobie na clustrze #azure Databricks.
Chciałem z poziomu lokalnego projektu, który sobie pisze w Intellij dobrać się do komponentu KeyVault na moim koncie Azure, żeby przeczytać Secrets tam
#programowanie #szkolenia #pracbaza
Hej przyjaciele,
W moim januszsofcie mamy taki dobrobyt, że raz w roku mam możliwość wybrania sobie jakiejkolwiek konferencji na, którą chcemy sobie pójść. Wchodzi w to lot, hotel, bilety itp.
Dogadałem się z moim przełożonym, że w tym roku nie chce nigdzie lecieć i może mógłbym ten budżet przeznacozny na mnie wykorzystać inaczej. Padła propozycja, że mogę pójść na jakieś dowolne szkolenie z zakresu IT/programowania/architektury
Hej przyjaciele,
W moim januszsofcie mamy taki dobrobyt, że raz w roku mam możliwość wybrania sobie jakiejkolwiek konferencji na, którą chcemy sobie pójść. Wchodzi w to lot, hotel, bilety itp.
Dogadałem się z moim przełożonym, że w tym roku nie chce nigdzie lecieć i może mógłbym ten budżet przeznacozny na mnie wykorzystać inaczej. Padła propozycja, że mogę pójść na jakieś dowolne szkolenie z zakresu IT/programowania/architektury
@inny_89: dam #programista15k dla zasięgu :D
#programowanie dla atencji: #programista15k
Koledzy i koleżanki,
Mam problem dotyczący #azure #databricks. Będzie dłuższy wpis.
Mam postawiony cluster na Azur Databricks, do którego chciałbym się łączyć i pracować z kodem/notebookami zdalnie z mojego laptopa przez
Koledzy i koleżanki,
Mam problem dotyczący #azure #databricks. Będzie dłuższy wpis.
Mam postawiony cluster na Azur Databricks, do którego chciałbym się łączyć i pracować z kodem/notebookami zdalnie z mojego laptopa przez

zna sie tu ktoś na databricksie?
Zastanawiam sie czemu logi widoczne w stdout poszczególnych jobów w Web UI nie są widoczne w stdout calego runa joba..
#devops #databricks
Zastanawiam sie czemu logi widoczne w stdout poszczególnych jobów w Web UI nie są widoczne w stdout calego runa joba..
#devops #databricks
Chyba, ze mnie uprzedzisz i uda Ci się zrobić dobry benchmark przede mną.
To wołąj wtedy mirku.
Poniżej jego odpowiedź odnośnie performencu na IO więc trochę może dać to pogląd dlaczego ZIO na SParku może mieć sens.
Aczkolwiek martwi mnie, ze on takich benchmarków wcześniej nie zrobił xD
źródło: comment_1636121185N4s0Pmud1Qz7b7i3UG7SnK.jpg
Pobierz