
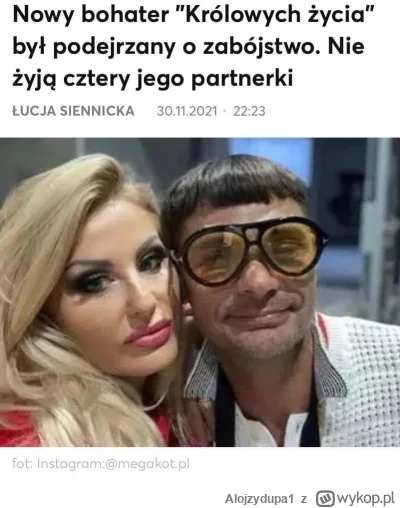
#csiwykop doprowadziło mnie w kolejne odmęty internetu. Tym razem na tapet #megakot który już tu kilkukrotnie się pałętał…
#pandoragate #polskiyoutube
Źródło: https://m.facebook.com/story.php?story_fbid=pfbid0nW5SQ51TAjwwLwK6VGekLCmqwwngsADapRzf6dZE245TDPb7Jissw1HW5ZEBbmwDl&id=100044387020898
#pandoragate #polskiyoutube
Źródło: https://m.facebook.com/story.php?story_fbid=pfbid0nW5SQ51TAjwwLwK6VGekLCmqwwngsADapRzf6dZE245TDPb7Jissw1HW5ZEBbmwDl&id=100044387020898












{kind=link}
{kind=link}
{kind=link}
{kind=link}
• [1] Poprawa efektywności LLM-ów wykorzystywanych w RAG-ach
Naukowcy z Google Cloud analizują wyzwania związane z wykorzystaniem modeli językowych o długim kontekście (LLM) w systemach generacji wspomaganej wyszukiwaniem (RAG). Odkryli oni, że samo zwiększenie liczby pobranych fragmentów może w rzeczywistości obniżyć wydajność ze względu na wprowadzenie nieistotnych informacji, które "dezorientują" LLM.
Aby rozwiązać te problemy, badacze proponują trzy metody:
a) zmianę kolejności wyszukiwania,
źródło: Vampires are make-believe, just like elves, gremlins and Eskimos
Pobierzhttps://streamable.com/e2jejj
Tu jeszcze lepsze przykłady:
https://swivid.github.io/F5-TTS/#speed-control