Aktywne Wpisy

ja chciałem tylko napisać, że Psy>>>>>>>>chatki z gówna>>>>>>>długo długo nic>>>>>>>>>>>>koty
nie ma z tych dachowców żadnego pożytku, są #!$%@?ące i nie są słodkie ani piękne. No ogólnie to koty #!$%@?ć prądem o dużym napięciu a Psy wychwalać
a każdy kto wrzuca zdjęcia rzekomo "śmiesznych i słodkich kotków" odznacza się brakiem rozumu i godności człowieka
Dobranoc.
#oswiadczenie #takaprawda #psy #zwierzaczki #koty
nie ma z tych dachowców żadnego pożytku, są #!$%@?ące i nie są słodkie ani piękne. No ogólnie to koty #!$%@?ć prądem o dużym napięciu a Psy wychwalać
a każdy kto wrzuca zdjęcia rzekomo "śmiesznych i słodkich kotków" odznacza się brakiem rozumu i godności człowieka
Dobranoc.
#oswiadczenie #takaprawda #psy #zwierzaczki #koty

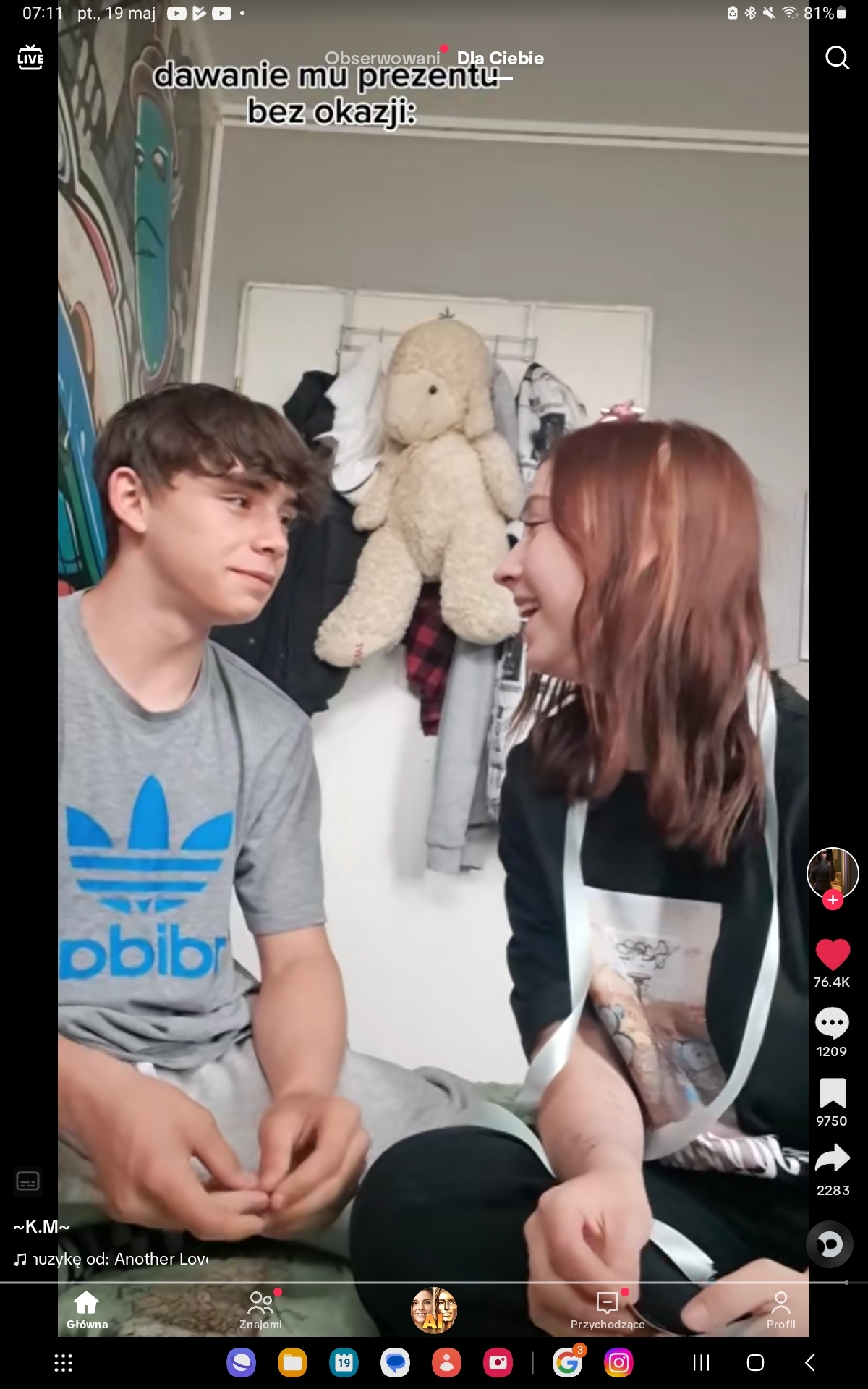
Prawie się popłakałem jak zobaczyłem tą zakochaną parę na tiktoku. Ja już nigdy nie będę miał 15 lat i nigdy nie przeżyję nastoletniej miłości. Jestem dorosły, mój czas na pierwsze miłości już minął. Ten widok mnie strasznie zabolał, oni na siebie patrzą jak w obrazki święte a na mnie nigdy nikt tak nie spojrzy.
#przegryw
#przegryw
{kind=link}
Aktywne Znaleziska





cześć,
głowię się i szukam rozwiązania swojego problemu, może coś doradzicie?:
zajmuję się wyszukiwarką w BigData od strony architektury, mam dużo grupowań więc zrezygnowałem z elasticsearch, poza tym pliki w ORC, ale da radę przenieść do innego formatu, tylko jakiego silnika najlepiej użyć? AWS here, Athena jest słaba (max 20-80 zapytań na 1s, a ja potrzebuję tak około 200-500 na 1s). Sensowny Redshift jest mega drogi... Znacie coś godnego polecenia, nie koniecznie AWS?
Skala to grupowanie/wyszukiwanie po około 20mln rekorów tygodniowo, z akumulacją do 1 miesiąca, baza przyrostowa, grupowana po przynajmniej 5 kolumnach