Aktywne Wpisy

maikeleleq +5
Pytanie bez ściemniania
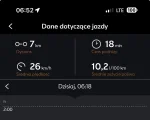
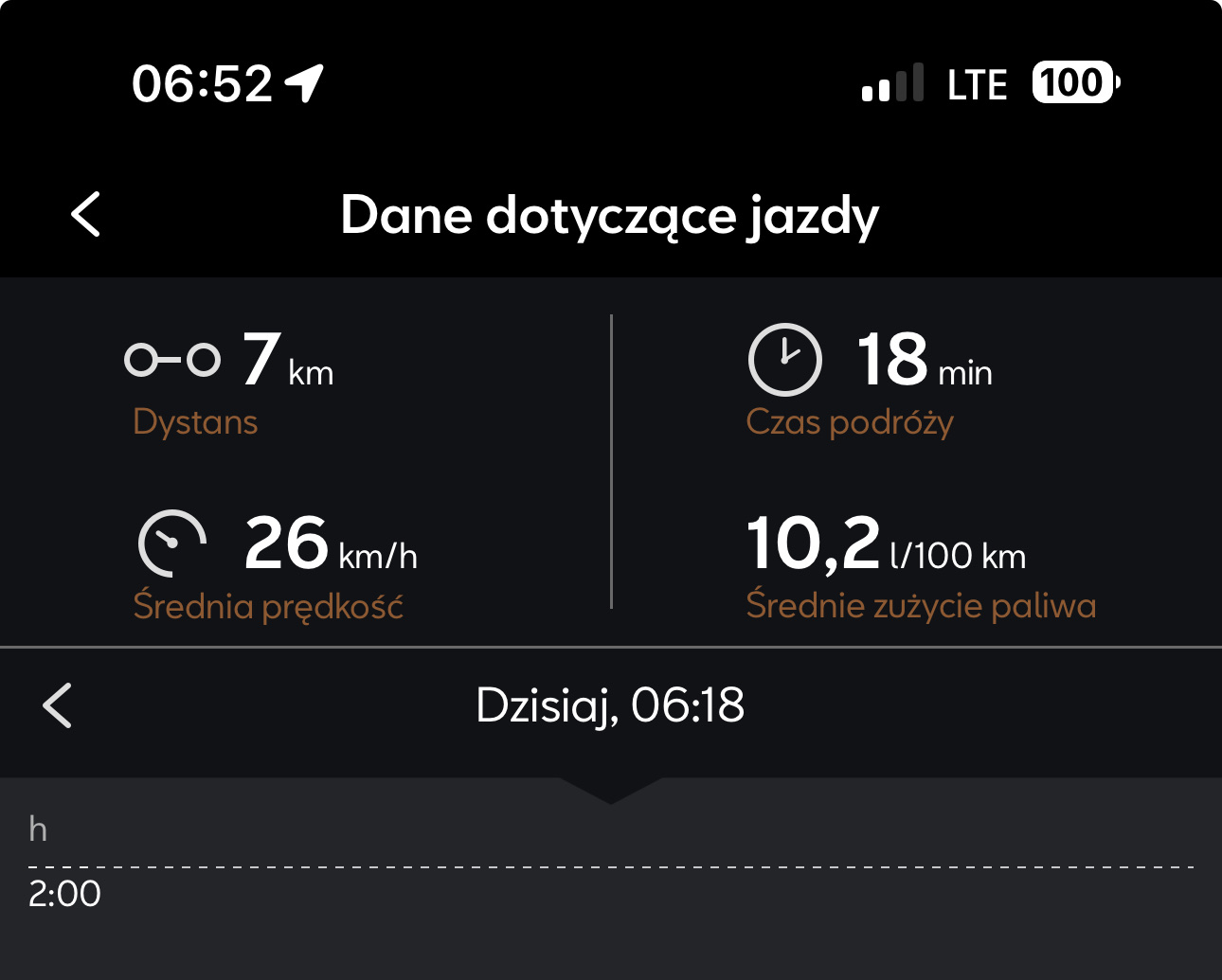
Ile wasze auta palą w mieście? Sprawdźmy kto robi najoszczędniejsze silniki ( ͡° ͜ʖ ͡°)
Na codzień jeżdżę Cuprą Formentor, 1.5TSI 150km, spalanie w okolicach 9.8L - 11L, jeżdżę tylko po Poznaniu co jest dość ważne jeśli chodzi o korki ( ͡° ͜ʖ ͡°)
#motoryzacja #samochody
Ile wasze auta palą w mieście? Sprawdźmy kto robi najoszczędniejsze silniki ( ͡° ͜ʖ ͡°)
Na codzień jeżdżę Cuprą Formentor, 1.5TSI 150km, spalanie w okolicach 9.8L - 11L, jeżdżę tylko po Poznaniu co jest dość ważne jeśli chodzi o korki ( ͡° ͜ʖ ͡°)
#motoryzacja #samochody
źródło: Zdjęcie z biblioteki
Pobierz
Miguelos +191





{kind=link}
{kind=link}
Z tego co widzę to domyślny kompilator Rusta wykorzystuje LLVM, a do C++ przecież też jest Clang na LLVM. Więc dlaczego sam język miałby sprawiać że jeden czy drugi kod maszynowy będzie szybszy?
Czy chodzi o to że jakiś język w lepszy sposób wyraża pewne założenia dla kompilatora i ten może poczynić więcej optymalizacji?
Czy bardziej o to że np. frontend C++ dla LLVM jest bardzie dopracowany niż frontent Rusta i generuje lepszej jakości LLVM IR? Ale czy wtedy porównanie wydajności języków nie zamienią się w porównanie wydajności frontendów kompilatorów?
#programowanie #rustlang #cpp #informatyka
@Passer93: poniekąd tak. Dużo łatwiej jest napisać wyżyłowany kompilator dla C, gdzie język jest praktycznie "przenośnym assemblerem" i jest projektowany z myślą o kompilatorach (np. wprowadza się keywordy specjalnie dla nich -
restrict,register) niż dla języka o bardzo wysokim poziomie abstrakcji, gdzie masz dużo więcej konstrukcji, idiomów@Passer93: tak. Np. w Ruscie nie masz problemów z aliasowaniem, przez co kompilator może czasem poczynić optymalizacje niemożliwe w innym wypadku. W innych wypadkach frontend może wypluć kod lepszej jakości, który będzie łatwiej przełknąć w backendzie. Ogólnie w takich językach starasz się porównać wydajność idiomatycznego kodu, bo to taki chcesz
1. brandzlowanie się do minimalnych różnic wydajności między językami i kompilatorami kiedy przepisanie kodu z lepszymi strukturami danych i unikając cache miss często przyśpieszy go 1000-krotnie jest bez sensu. Jak chcesz mieć szybki kod to zastanów się jakie operacje będziesz wykonywał i jak zaprojektować struktury danych żeby te operacje nie ruszały dużych obszarów pamięci. A potem puści profiler i zoptymalizuj co większe hotspoty.
2. jeśli już wchodzimy w kwestie różnych
Na pewno inaczej będzie dla dynamicznych traitów niż metod wirtualnych bo mają inną zasadę działania.
Myślę, że warto by też porównać np Arc z
std::shared_ptr.Ciekawi mnie jak jest z lambdami, szczególnie że Rust posiada FnOnce.
Z drugiej strony Rust w niektórych wersjach nie korzystał z tego założenia,
@Saly: Jeśli chodzi o kompilacje pod dany procesor w C++ to w gcc flagi
-marchi-mtunepozwalają to osiągnać. Co do setupu pod LTO to nie mam pojęcia jak to wygląda, ale z tego co pamiętam to PGO w gcc było całkiem lajtowe, najpierw się budowało execa z dodatkową flagą, potem się normalnie profilowało program który podczas runtime generował dodatkowy plik z