Aktywne Wpisy
o__0 +242
{kind=link}
ryszard-kulesza +209
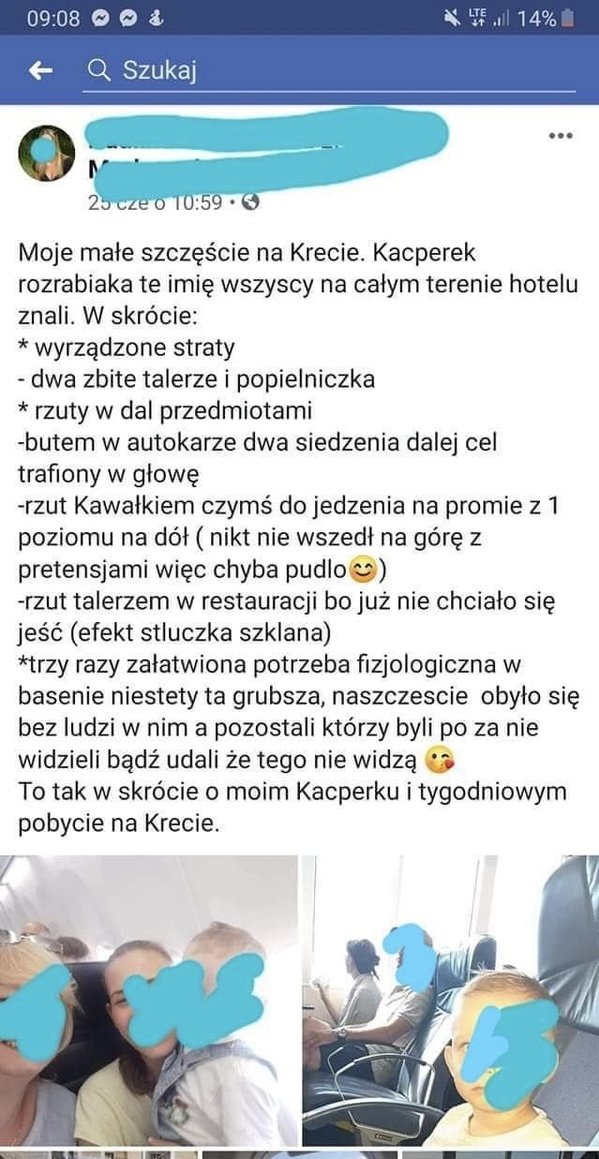
Czy ja dobrze zauważyłem, że wykopki zbiorowo uznały, że coś tak powszechnego w naszej cywilizacji, jak posiadanie psa jako zwierzęcia domowego jest "lewackie"? xDDD
Jakieś brednie o "julkach", "psieckach" tak jakby tylko takie osoby posiadały psy, ogółem traktowanie psiarzy, jakby ich pupile były jakąś nowomodną fanaberią wymyśloną przez lewicę xD
#psy #bekazpodludzi #bekazwykopkow
Jakieś brednie o "julkach", "psieckach" tak jakby tylko takie osoby posiadały psy, ogółem traktowanie psiarzy, jakby ich pupile były jakąś nowomodną fanaberią wymyśloną przez lewicę xD
#psy #bekazpodludzi #bekazwykopkow

źródło: licensed-image
Pobierz{kind=link}
Aktywne Znaleziska





Takie dziwne zjawisko napotkałem: Gdy trenuję model do gry z dużą ilością dropoutów i do walidacji używam danych poprzedzających dane wykorzystane do treningu to trafność walidacji jest większa o kilka % od trafności uzyskanej podczas treningu (czyli w normie). Jeśli jednak do walidacji używam danych wyprzedzających dane treningowe to im większa jest trafność treningowa to trafność walidacji spada - i to poniżej wartości wynikającej z prawdopodobieństwa. Jak dla mnie trochę #creepy ( ͡º ͜ʖ͡º). Teraz np. trafność treningowa wynosi ~80% a testowa (dla danych nowszych niż treningowe) to ~42%, gdzie 50% wynikałoby z wyborów losowych.