Aktywne Wpisy

goodbadbye +92
jadę dziś odebrać samochód od mechanika i muszę mu oddać 3/4 mojej wypłaty, jestem załamana ryczeć mi się chce

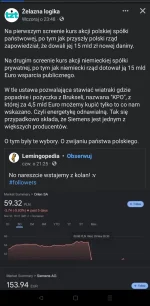
Dla tych ślepo zakochanych w nowym rządzie. Poczytajcie sobie czasem coś głębszego
#sejm #koalicjaobywatelska
#sejm #koalicjaobywatelska
{kind=link}
Aktywne Znaleziska





1.)
from sklearn.modelselection import traintestsplit
X-train, X-tesy, y-train, y-test = train-test-split(X, y, test_size =0,25, stratify = y)
- stratify = y oznacza, że metoda train-test-split zwróci y-train i y-test z taką samą ilością wierszy
- jak wygląda sprawa z ilością wierszy w X-train porównując z resztą zestawów?
2.)
Chcę zbudować sieć CNN, która ma klasyfikować obrazy (10 klas obrazów), ostatnia warstwa powinna wyglądać jak poniższa?
tf.keras.layers.Conv2D(64, (3,3), padding=valid', activation=tf.nn.relu)
#programowanie #machinelearning #python
Tutaj masz sytuację że X-train będzie miał około 75%