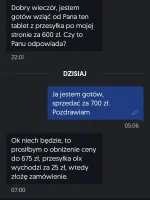
żeby nie liczyć za każdym razem niepotrzebnie count(*), chce wykonać coś jak if existst(zapytanie limit 100 000,1) then '>100 000' else count(*) from zapytanie; czyli jeśli nie istnieje wynik 100 001 to znaczy że jest mniej wyników i należy policzyć dokładną ich ilość
obecnie gdy zapytanie zawiera np 50 tys wyników, najpierw wykonuje się exists a następnie 'od nowa' drugie zapytanie co wydłuża czas w przypadku zapytań z niewielką liczbą wyników jak to przyśpieszyć?
select min(c) from ( select 100001 as c from table union select count(*) as c from table ) (nie mam SQL pod ręką, nie mam jak tego przetestować, ale coś podobnego powinno zadziałać)
">" sobie dodaj we frontendzie, albo pokombinuj ifami.
SELECT CASE WHEN podzapytanie.liczbaczegoś >= 100001 THEN '>100000' ELSE podzapytanie.liczbaczegoś FROM (COUNT(*) AS liczbaczegoś FROM zapytanie LIMIT 100001) AS podzapytanie


{kind=link}





if existst(zapytanie limit 100 000,1) then '>100 000' else count(*) from zapytanie;
czyli jeśli nie istnieje wynik 100 001 to znaczy że jest mniej wyników i należy policzyć dokładną ich ilość
obecnie gdy zapytanie zawiera np 50 tys wyników, najpierw wykonuje się exists a następnie 'od nowa' drugie zapytanie co wydłuża czas w przypadku zapytań z niewielką liczbą wyników
jak to przyśpieszyć?
#sql #programowanie
select min(c) from ( select 100001 as c from table union select count(*) as c from table )(nie mam SQL pod ręką, nie mam jak tego przetestować, ale coś podobnego powinno zadziałać)
">" sobie dodaj we frontendzie, albo pokombinuj ifami.
nie wystarczy select count() from (zapytanie limit 100001) i potem we frontendzie zamieniasz 100001 na >100000?
SELECT CASE WHEN podzapytanie.liczbaczegoś >= 100001 THEN '>100000'ELSE podzapytanie.liczbaczegoś
FROM (COUNT(*) AS liczbaczegoś FROM zapytanie LIMIT 100001) AS podzapytanie
@asciiterror: to ma sens