Aktywne Wpisy

1-1-1-1 +226
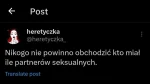
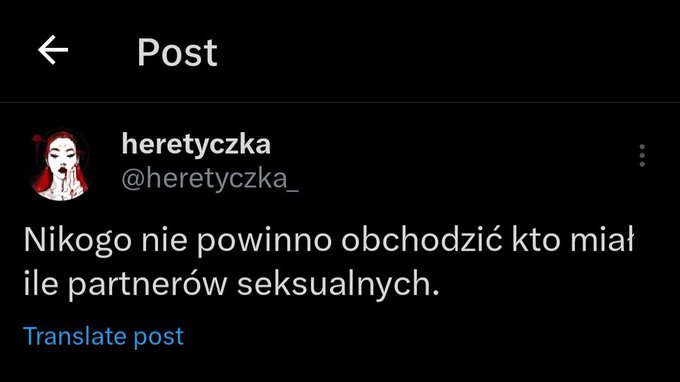
Dlaczego dla Julek to pytanie sprawia taki problem? Przecież to najlepszy filtr na prawaków/mizoginów. Mówisz, że miałaś 50 i chłopy same się odfiltrują xD Chyba nie boisz się, że niepoprawna odpowiedź zabije produkcję copium w głowie twojego amanta?
#blackpill #p0lka #redpill #bekazlewactwa
#blackpill #p0lka #redpill #bekazlewactwa
źródło: 123aa
Pobierz
ivan777 +224





{kind=link}
{kind=link}
próbuję zrobić sobie scrapera do komiksu internetowgo, żeby zrozumieć jak działa beautifulsoup. No i nie wiem czemu, ale mi nie idzie :( Wybrałem sobie stronkę: https://www.gocomics.com/sarahs-scribbles/2018/09/02 i chcę ściągnąć adres komiksu używając bs4.
Mam coś takiego:
res = requests.get(url)
soup = bs4.BeautifulSoup(res.text)
comic_strip = soup.select('div, [data-title*="Sarah\'s Scribbles for"]')
Niestety kiedy drukuję sobie comic_strip, to otrzymuję z powrotem pół kodu strony zamiast tylko tego elementu. :( Jakiś pro mógłby mi podpowiedzieć co robię źle i jak najprościej wyciągnąć tylko atrybut data-url? Dzięki!
#python
Bo to jest mniej więcej tak różnica:
- znajdź mi diva wewnątrz którego jest coś co ma data-title
- znajdź mi diva który ma data-title
a następnie:
comic_strip[0]['data-url']comic_strip = soup.select_one('div.comic.container')