Wczoraj pytałem o możliwość wczytania tabel z Apache Drilla do Informatica PowerCenter, temat nadal nierozwiązany, ale stwierdziłem, że opiszę szerzej bo ciekawi mnie niezmiernie czy uda mi się to rozgryźć. Póki co założyłem sobie pierwszy cel jakim jest zaczytanie infą tabel (kolekcji?) #mongodb na których stoi Drill. Skonfigurowałem połączenie ODBC, klikam connect w infie żeby wczytać źródła, mongo potwierdza to statusem connect po swojej stronie, ale nie widzę żadnych collectów.
Wszystko
Najnowsze
Archiwum

puchacz22
Dlaczego i do czego wykorzystać Hadoop

Jak to się stało, że akurat ta technologia, pomimo wad i problemów wieku dziecięcego, stała się tak istotnym elementem mega trendu Big Data? Aby odpowiedzieć na to pytanie spróbujmy przyjrzeć się procesowi powstania i rozwoju Hadoopa jako oprogramowania, ale także towarzyszącemu mu...
z- 0
- #
- #
- #
- #
- #
- #

Po malej przerwie dzisiaj w Packt'cie za darmo:
HBase Design Patterns
https://www.packtpub.com/packt/offers/free-learning
#packtpub #bazydanych #hadoop
HBase Design Patterns
https://www.packtpub.com/packt/offers/free-learning
#packtpub #bazydanych #hadoop


Tomek7
@programistalvlhard: Tak na teraz nic sobie nie przypominam, ale coś sobie przypomnę to dam znać. Generalnie ogarnij podstawy MR, ale nie skupiaj się tylko na kodzie - bo to w sumie proste - poczytaj też o data locality, po co HDFS i jak obsługiwać YARNa, który jest naprawdę dobry i nawet inne frameworki z niego korzystają do zarządzania zasobami
zajety_login
@programistalvlhard: Moim zdaniem powinieneś zacząć od Sparka, który jest dużo łatwiejszy, przyjemniejszy i wydajniejszy niż Hadoop MapReduce. Zaczynając od tego drugiego możesz się niestety szybko zrazić :P No i musisz pamiętać o tym że Hadoop składa się z trzech modułów (MapReduce, YARN, HDFS) i że Spark jest konkurencją tylko wobec tego pierwszego. Z dwoma pozostałymi i tak będziesz miał styczność pisząc aplikacje Sparkowe.

Hadoop Real-World Solutions Cookbook
https://www.packtpub.com/packt/offers/free-learning
#programowanie #ebook #hadoop
https://www.packtpub.com/packt/offers/free-learning
#programowanie #ebook #hadoop
#programowanie #hadoop #ebook
Darmowa "Apache Kafka"
https://www.packtpub.com/packt/offers/free-learning/
Darmowa "Apache Kafka"
https://www.packtpub.com/packt/offers/free-learning/
Od czego zacząć naukę Hadoopa? Jakie środowisko do obsługi tego ciężaru? Książki (pozycje z it-ebooks wskazane). Chciałbym zrobić w tym pierwsze kroki ale nie chcę się od razu w--------ć w coś, czego nie ogarnę, bo to zniechęca.
#hadoop #bigdata #businessintelligence
#hadoop #bigdata #businessintelligence


Treść przeznaczona dla osób powyżej 18 roku życia...
@fledgeling: ORACLE DATABASE DATABASE NO TROUBLE

Komentarz usunięty przez autora
#bigdata #hadoop #mirkostatbotdev #hadooplearning
Moja stara Javowa implementacja Mirkostatbota chyba troszkę szybciej działała niż ta uber-hadoopowa wersja która liczy ledwo kilka podstawowych statów ;)
Moja stara Javowa implementacja Mirkostatbota chyba troszkę szybciej działała niż ta uber-hadoopowa wersja która liczy ledwo kilka podstawowych statów ;)

źródło: comment_Jp8TSvmvAZGP4ibKZQHtDtVkv6WvSgME.jpg
Pobierz@pulse: Tak, ale z tego co wiem to tylko do streamingu i processowania danych w pamieci. Mało wiem i o Sparku i o Hadoopie jeszcze :D
@Grizwold: tez nie za wiele wiem.
mignal mi dzisiaj art http://opensource.com/business/15/1/apache-spark-new-world-record i skojarzylo mi sie z twoim wpisem ( ͡° ͜ʖ ͡°)
mignal mi dzisiaj art http://opensource.com/business/15/1/apache-spark-new-world-record i skojarzylo mi sie z twoim wpisem ( ͡° ͜ʖ ͡°)
#hadoop #bigdata #hortonworks
Zna ktos jakieś dobre materiały do konfiguracji klastra (3 nodes - sandbox odpada) od zera do odpalenia wordcount?
Mile widziane także materiały korzystające z Ambari. :)
Zna ktos jakieś dobre materiały do konfiguracji klastra (3 nodes - sandbox odpada) od zera do odpalenia wordcount?
Mile widziane także materiały korzystające z Ambari. :)

@Grizwold: Do Ambari powinna wystarczyć dokumentacja ze stronki Hortona. A tak poza tym to może Hadoop Operations i do konfiguracji samego OS-a można się wspomóc papierkiem wypuszczonym przez Della.
@Grizwold: Nie powinno być większych problemów - jak dokładnie zrobisz to co w dokumentacji, to Ambari w większości przypadków sobie poradzi. Co do stronki z GUI: zainstaluj sobie manualnie Hue - jest w repo pakietów Hortona. Potem trzeba go jeszcze ręczenie dokonfigurować (namiary na serwery itp) przez edycję hue.ini. To też jest krótko opisane w dokumentacji.

{kind=link}
{kind=link}
{kind=link}
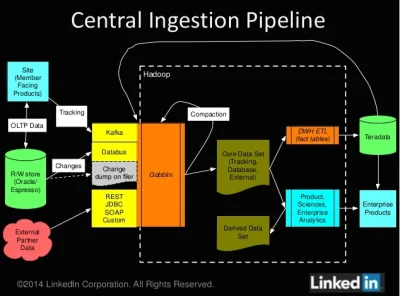
LinkedIn explains its complex Gobblin big data framework
LinkedIn shed more light Tuesday on a big-data framework dubbed Gobblin that helps the social network take in tons of data from a variety of sources so that it can be analyzed in its Hadoop-based data warehouses.
https://gigaom.com/2014/11/26/linkedin-explains-its-complex-gobblin-big-data-framework/
#
LinkedIn shed more light Tuesday on a big-data framework dubbed Gobblin that helps the social network take in tons of data from a variety of sources so that it can be analyzed in its Hadoop-based data warehouses.
https://gigaom.com/2014/11/26/linkedin-explains-its-complex-gobblin-big-data-framework/
#
źródło: comment_EUKIpMU7RRnZIokqO1tGYrITqQteASWL.jpg
Pobierz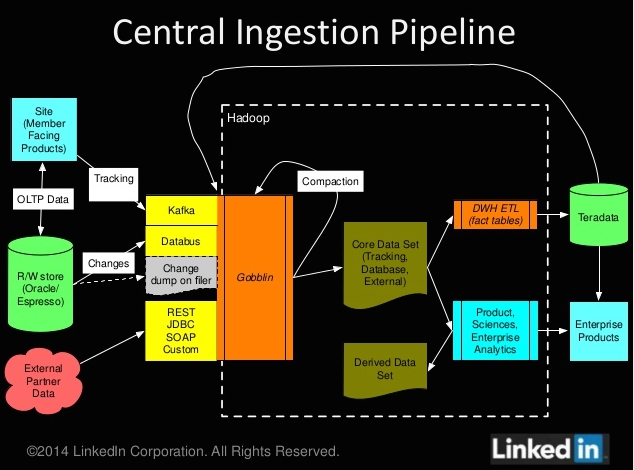{kind=link}
Apache Hive 0.14
http://hortonworks.com/blog/announcing-apache-hive-0-14/
#bigdata #hadoop #hive
#msqspam
http://hortonworks.com/blog/announcing-apache-hive-0-14/
#bigdata #hadoop #hive
#msqspam
Building a complete Tweet index
https://blog.twitter.com/2014/building-a-complete-tweet-index
#bigdata #hadoop i troche w sumie #webdev
#msqspam
https://blog.twitter.com/2014/building-a-complete-tweet-index
#bigdata #hadoop i troche w sumie #webdev
#msqspam
Interesujace materialy Adama kawy, zajmującego się #bigdata w spotify
http://www.slideshare.net/AdamKawa
http://hakunamapdata.com/
#
http://www.slideshare.net/AdamKawa
http://hakunamapdata.com/
#
Getting started with Hadoop MapReduce
http://blog.eviac.net/2014/11/getting-started-with-hadoop-mapreduce.html
#hadoop #mapreduce #bigdata
#msqspam
http://blog.eviac.net/2014/11/getting-started-with-hadoop-mapreduce.html
#hadoop #mapreduce #bigdata
#msqspam
Best of Strata Conference + Hadoop World 2014
https://www.youtube.com/playlist?list=PL055Epbe6d5bjXYRpxLiXy_-bnPCzRCSU&imm_mid=0c5d92&cmp=em-strata-na-na-newsltr_20141029
#bigdata #hadoop #ai
#msqspam
https://www.youtube.com/playlist?list=PL055Epbe6d5bjXYRpxLiXy_-bnPCzRCSU&imm_mid=0c5d92&cmp=em-strata-na-na-newsltr_20141029
#bigdata #hadoop #ai
#msqspam
eBay open sources a big, fast SQL-on-Hadoop database
eBay has open sourced a database technology, called Kylin, that takes advantage of distributed processing and the HBase data store in order to return faster results for SQL queries over Hadoop data
https://gigaom.com/2014/10/22/ebay-open-sources-a-big-fast-sql-on-hadoop-database/
#
eBay has open sourced a database technology, called Kylin, that takes advantage of distributed processing and the HBase data store in order to return faster results for SQL queries over Hadoop data
https://gigaom.com/2014/10/22/ebay-open-sources-a-big-fast-sql-on-hadoop-database/
#
Docker Ships HDP Into the Cloud
http://hortonworks.com/blog/docker-ships-hdp-cloud/
#docker #hadoop #bigdata
#msqspam
http://hortonworks.com/blog/docker-ships-hdp-cloud/
#docker #hadoop #bigdata
#msqspam