Aktywne Wpisy

timechain +31
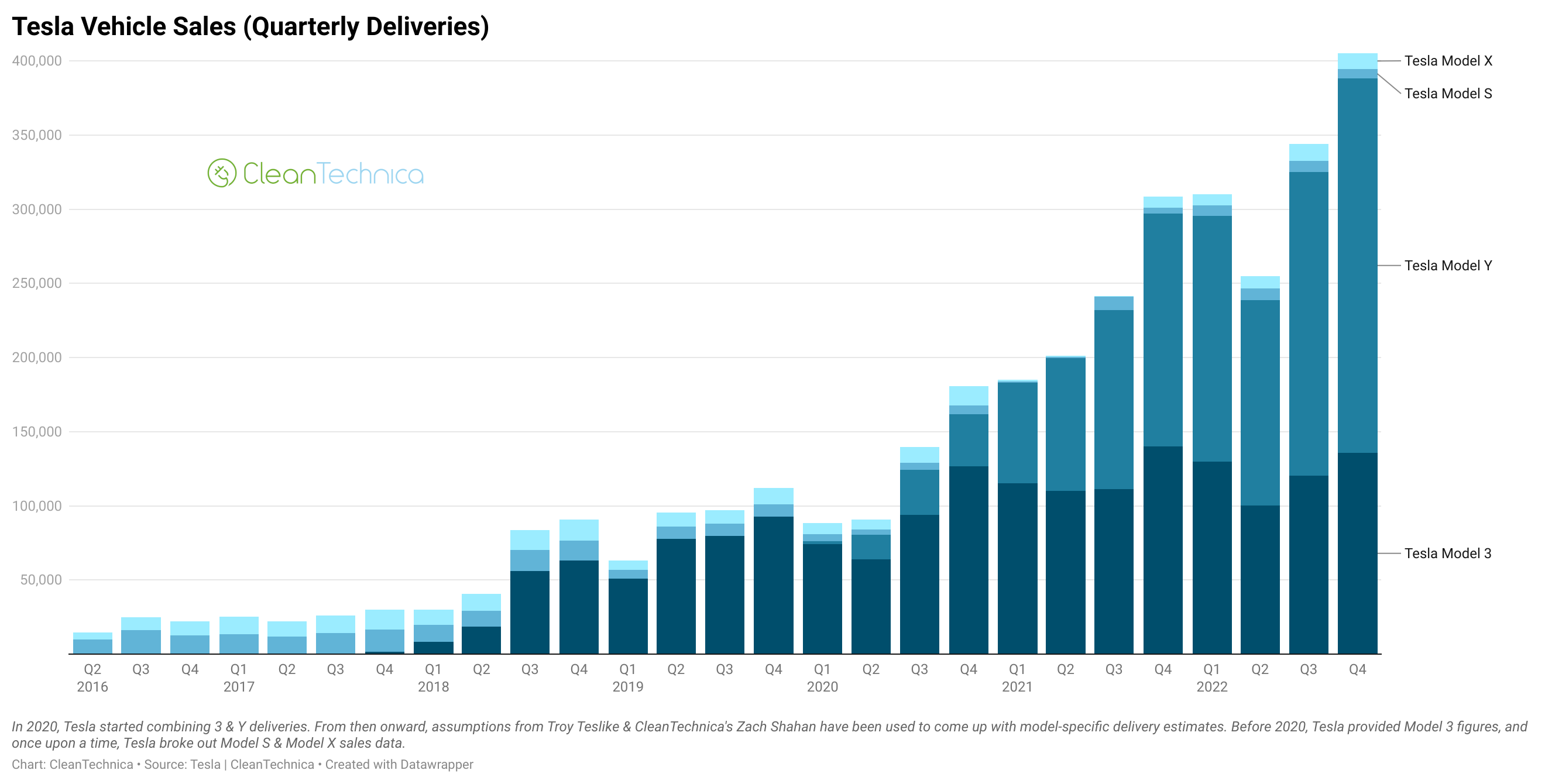
Polacy pokochali elektryki. Tesla w czołówce najbardziej pożądanych samochodów
Kisnę z wypopków. Zbiorowisko małoletnich przegrywów. Wieczna walka z elektrykami i wytykanie jakie są gówniane a prawda jest taka że mają ból dupy bo ich nie stać. Tytani intelektu nie rozumieją że elektryki będą bardzo szybko taniały... Widzicie wypopki, sprzedaż Tesli rośnie na całym świecie pomimo tego że są tak gówniane jak twierdzicie. I NIKT TUCH LUDZI NIE "ZNIEWOLIŁ" FOLIARZE, NIKT ICH NIE
Kisnę z wypopków. Zbiorowisko małoletnich przegrywów. Wieczna walka z elektrykami i wytykanie jakie są gówniane a prawda jest taka że mają ból dupy bo ich nie stać. Tytani intelektu nie rozumieją że elektryki będą bardzo szybko taniały... Widzicie wypopki, sprzedaż Tesli rośnie na całym świecie pomimo tego że są tak gówniane jak twierdzicie. I NIKT TUCH LUDZI NIE "ZNIEWOLIŁ" FOLIARZE, NIKT ICH NIE


EarpMIToR +12






{kind=link}
#vps #hosting #raspberrypi
Ja postawiłem sobie lokalnie cluster z Raspberry Pi pod dowództwem Docker Swarm i aktualnie 3 malinki są jego częścią, plus jedna osobno na bazę danych.
@devones: właśnie chyba skończę na jednym z tych rozwiązań, chociaż bardziej z tego powodu, że nie wiem ile zasobów będę potrzebował. Pierwsze crawlery już pisałem i używałem, ale po raz pierwszy będę chciał na poważnie coś postawić.
@xDrope: Jak chcesz potestować digitalocean nie zapomnij wpisać w google "digitalocean trial" - znajdziesz 100$ na pierwsze 60 dni bezpłatnie ( ͡° ͜ʖ ͡°)
@devones: ( ͡° ͜ʖ ͡°) dzięki, będzie śmigane