Wszystko
Najnowsze
Archiwum
@marqustd: Nie używałem tej biblioteki, ale zgodnie z dokumentacją:
dla 699 -> "^699$"
dla ciągu wyrazów ->
przy czym ciągi wyrazów mogą być puste
dla 699 -> "^699$"
dla ciągu wyrazów ->
"^\S*?(-\S*?)*$"przy czym ciągi wyrazów mogą być puste
Mireczki, potrzebuję takiego regexa, który wyciągnie mi dowolny ciąg znaków do końca lub pierwszej napotkanej kropki z wyłączeniem jednej frazy - "abcdef",
"index.html" -> "index"
"abcdef" -> brak dopasowań
"index2" -> "index2"
#programowanie #wyrazeniaregularne #regex
"index.html" -> "index"
"abcdef" -> brak dopasowań
"index2" -> "index2"
#programowanie #wyrazeniaregularne #regex
@Nemeczekes: niestety to musi być w jednym wyrażeniu.
język - java
język - java


#programowanie #regex #wyrazeniaregularne
Mirki, poratujecie :(
Parser zwraca mi ze strony dane w formacie: {"text":"3 498,96 zł/m²"}. Jakie wyrażenie regularne zamieni zwrot na 3498,96?
Mirki, poratujecie :(
Parser zwraca mi ze strony dane w formacie: {"text":"3 498,96 zł/m²"}. Jakie wyrażenie regularne zamieni zwrot na 3498,96?
@ZapomnialWieprzJakProsiakiemByl: spacja do wy....kasowania.
@wytrzzeszcz: @krzysztof114: ogarnąłem. Wielkie dzięki za naprowadzenie :) Powinno być: [^0-9,]
Mirki, pytanko mam szybciutkie do was, chciał bym nauczyć się wyrażeń regularnych w #php. Wymyśliłem sobie zadanie, mam jakiś string, wewnątrz niego jakieś teksty i kilka linków:
test
oraz kilka innych, np:
test2
teraz chciał bym wyciągnąć to co jest między znacznikami ten tekst, pamiętajmy że link może mieć klasę, title itd. ale nie
test
oraz kilka innych, np:
test2
teraz chciał bym wyciągnąć to co jest między znacznikami ten tekst, pamiętajmy że link może mieć klasę, title itd. ale nie

@Govr: najprościej chyba
i wtedy pierwszą tablice będziesz miał całość tego wyrażenia, a w każdej kolejnej nawiasy, w tym przypadku "tutaj" dla każdej złapanej linii.
Przy okazji polecam sobie testować regexy np tu. http://www.phpliveregex.com/
EDIT: w sumie to nie do końca odpowiedziałem na Twoje pytanie, w każdym razie oprócz całości wyrażenia to nawiasami () wyciągasz te dane, które chcesz zachować. Nie słyszałem o pomijaniu całości
(.*?)i wtedy pierwszą tablice będziesz miał całość tego wyrażenia, a w każdej kolejnej nawiasy, w tym przypadku "tutaj" dla każdej złapanej linii.
Przy okazji polecam sobie testować regexy np tu. http://www.phpliveregex.com/
EDIT: w sumie to nie do końca odpowiedziałem na Twoje pytanie, w każdym razie oprócz całości wyrażenia to nawiasami () wyciągasz te dane, które chcesz zachować. Nie słyszałem o pomijaniu całości
konto usunięte via Android
@rzezimieszek_ dzieki, jak będę w domu to potestuje.
Mam łańcuch znaków w postaci XAX, gdzie X to pewien znak powtórzony określoną ilość razy, a A to łańcuch dowolnych znaków za wyjątkiem liczb i konkretnego podłańcucha znaków. Jak wyglądałoby wyrażenie regularne dla takiego łańcucha? Chodzi mi konkretnie o wykluczenie tego konkretnego podłańcucha z łańcucha A.
Przykład:
Przykład:
--------
Przykładowy tekst gdzie

Mam taki ciąg:
Próbuję stworzyć regex, który wyłapałby mi każdą z liczb z osobna i wrzucił do grupy. Chciałem łapać najpierw pierwszą liczbę, po czym łapać pary
1 2 23 54 24 (liczby rozdzielone spacjami, bez określonej długości liczby).Próbuję stworzyć regex, który wyłapałby mi każdą z liczb z osobna i wrzucił do grupy. Chciałem łapać najpierw pierwszą liczbę, po czym łapać pary
(spacja)(liczba).

jest jakiś sposób żeby z matchy pozbyć się dwukropków? :
https://regex101.com/r/ROavLw/1
#regex #wyrazeniaregularne
bo poźniej w kodzie mam takie paskudztwo
https://regex101.com/r/ROavLw/1
#regex #wyrazeniaregularne
bo poźniej w kodzie mam takie paskudztwo
> s.replace(emoticonRegex, '')
'text  '
Pany, potrzebuję pomocy w #wyrazeniaregularne #regexp
Mam sobie wzorzec
Zwróci mi binarki zawierające sekwencję trzech kolejnych jedynek. Potrzebuję wzorzec odwrotny. Kombinuję z [^] ale coś nie idzie. Pomoże ktoś?
#programowanie #pomocy
Mam sobie wzorzec
\b[01]*(1){3}[01]*\b
Zwróci mi binarki zawierające sekwencję trzech kolejnych jedynek. Potrzebuję wzorzec odwrotny. Kombinuję z [^] ale coś nie idzie. Pomoże ktoś?
#programowanie #pomocy
@IndieDevArt: @WybranyLoginJestZaj: chodzi o to aby zwróciło elementy które nie zawierają trzech kolejnych jedynek.

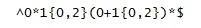
/().*(?=<\/h2>)/igmMam takie wyrażenie. Jak można wyłączyć z zaznaczania ``, tak aby tylko zostały same tytuły, które są wewnątrz tagów?
#wyrazeniaregularne #regexp #programowanie
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------


Witam regexpowe swiry,
Jako ze jestem leszczem w temacie, potrzebuje wyrazenie ktory dany string:
Wartosc1;Wartosc2;Wartosc3;ZnakSpecjalny=';';Wartosc4;Wartosc5;
zesplituje po ; na
Jako ze jestem leszczem w temacie, potrzebuje wyrazenie ktory dany string:
Wartosc1;Wartosc2;Wartosc3;ZnakSpecjalny=';';Wartosc4;Wartosc5;
zesplituje po ; na

([^;]+('[^']+')?);EDIT lepszy support:
([^;']*('[^']*')*)*;Komentarz usunięty przez autora
#naukaprogramowania #regex #wyrazeniaregularne
Czy to będzie dobry regex do daty w formacie YYYY-MM-DD?
Czy to będzie dobry regex do daty w formacie YYYY-MM-DD?
(0-9){4}\-(0-9){2}\-(0-9){2}
@Sir_Nick: nie bo przejdzie miesiac 99 i dzien 99, skorzystaj z jakiegoś datetime do walidacji daty czy da się utworzyć datę i tyle

@Sir_Nick:
nie bardzo, po pierwsze [0-9] a nie (0-9) jak range, i czemu escapy przed '-'? a abstrahując od tego że to będzie łapało więcej niż potrzeba to prościej \d{4}-\d{2}-\d{2}
nie bardzo, po pierwsze [0-9] a nie (0-9) jak range, i czemu escapy przed '-'? a abstrahując od tego że to będzie łapało więcej niż potrzeba to prościej \d{4}-\d{2}-\d{2}
Próbuję napisać takie wyrażenie, które wyłapie mi identyfikator wpisu tylko pod warunkiem, że podany link nie jest komentarzem na mikroblogu.
Próbowałem w ten sposób, że jeśli po id wpisu wystąpi
www.wykop.pl/wpis/17072663/#comment-59461313
Próbowałem w ten sposób, że jeśli po id wpisu wystąpi
#comment to #regexp nie powinien niczego znaleźć. Jednak nie działa.wpis\/(\d+)\/?(?!#comment)www.wykop.pl/wpis/17072663/#comment-59461313

@Matt23: To podaj rozwiązanie! Kiedy ludzie się nauczą?

źródło: comment_673kohfPgkt8s3jXQzyEwluVth3pUovP.jpg
Pobierz@niemaKlapka: To nie wypali gdy po slashu wystąpi opis z kilkoma pierwszymi wyrazami z początku wpisu, np:
www.wykop.pl/wpis/17080699/probuje-napisac-takie-wyrazenie-ktore-wylapie-mi-i
Moje rozwiązanie @a231:
/wpis\/(\d+)(\/(?!#comment)|$)/g
www.wykop.pl/wpis/17080699/probuje-napisac-takie-wyrazenie-ktore-wylapie-mi-i
Moje rozwiązanie @a231:
/wpis\/(\d+)(\/(?!#comment)|$)/g

Wołam speców od wyrażeń regularnych. Potrzebne mi wyrażenie, które wyłapie w tekście coś takiego:
href=3D"http://allegro.pl/coś tam.html."
np.: href=3D"
href=3D"http://allegro.pl/coś tam.html."
np.: href=3D"


Hej mirki, mam taką sprawę, problem w tym że pilną.. Mam katalog, który zawiera w sobie ogromną ilość podkatalogów, w których jest bardzo dużo małych plików.
Musze znaleźć te, które mają maksymalnie 4 znaki w nazwie pliku.
Rzecz się dzieje na windows 7, więc wymyśliłem, że najwygodniej będzie przez total commander przy użyciu wyrażeń regularnych, ale - jak to zapisać żebym w wyniku otrzymał to czego potrzebuje?
#algorytmy
#wyrazeniaregularne
Musze znaleźć te, które mają maksymalnie 4 znaki w nazwie pliku.
Rzecz się dzieje na windows 7, więc wymyśliłem, że najwygodniej będzie przez total commander przy użyciu wyrażeń regularnych, ale - jak to zapisać żebym w wyniku otrzymał to czego potrzebuje?
#algorytmy
#wyrazeniaregularne


Nokurdebela xD
Ktoś wie czemu ten regex nie chce mi się skompilować w javie?
^ O tutaj są 2 backslashe tylko wykop obcina ;_;
Zwraca
Ktoś wie czemu ten regex nie chce mi się skompilować w javie?
\x.{2}
^ O tutaj są 2 backslashe tylko wykop obcina ;_;
Zwraca

@Wyrewolwerowanyrewolwer: sam kiedyś miałem podobny problem, generalnie chodzi o to że czasem jak wpiszesz z łapy 4 backslashe (np jako argument), to najpierw kompilator escapuje 2 razy po 2 backlashe, a potem parser regexpa te już wyescapowane 2 backslashe escapuje do jednego ostatecznego. Wiem że nie umiem tłumaczyć i nie wiem czy dobrze mówię, ale to tak w skrócie ( ͡° ͜ʖ ͡°)

@Wyrewolwerowanyrewolwer: Rzecz jest w zasadzie prosta i znana we wszystkich jezykach. Masz tutaj dwa poziomy escapowania. Najpierw jest escapowanie stringow normalnie w jezyku programowania. Stad dziala np. "\n" jako nowa linia, a "\" zostawia w efekcie pojedynczy "\".
Drugi poziom to regex, w ktorym niestety tez "\" sluzy do escapowania. W efekcie jest tak jak napisal @hamster151:
W wielu
Drugi poziom to regex, w ktorym niestety tez "\" sluzy do escapowania. W efekcie jest tak jak napisal @hamster151:
"\" -> javac -> "\" -> regex -> "\"
W wielu

Z racji modernizacji skryptu chciałem taką jedną rzecz poprawić, stworzyłem takie:
wyrażenie reguralne. Jednak wynik jego w za pomocą re.findall zwraca pustą listę
Zaś tutaj na takich danych: zwraca wszystko co powinien: https://regex101.com/r/jT3qN3/2#python
(gmina_[0-9]+)".+?href="(.+?)".+;">(.+?)<wyrażenie reguralne. Jednak wynik jego w za pomocą re.findall zwraca pustą listę
Zaś tutaj na takich danych: zwraca wszystko co powinien: https://regex101.com/r/jT3qN3/2#python
@sylwke3100: w takim razie jeśli oczekujesz pomocy, to powinieneś pokazać więcej kodu. U mnie dodanie tego kodowania pomogło i wyłapało grupy.
Czy wyrażenia regularne działają jakoś inaczej w pythonie niż gdziekolwiek indziej?
Mam taki kod:
Szukam wyrazów, które zawierają w sobie którąś z sekwencji znaków 'math', 'is', 'fun'. Ten regex zdaje się działać testowany w przeznaczonych do tego serwisach. Jednak w powyższym kodzie if zwraca false. O co chodzi?
Mam taki kod:
q = re.compile('math|is|fun')
if q.match("smathfuni"):Szukam wyrazów, które zawierają w sobie którąś z sekwencji znaków 'math', 'is', 'fun'. Ten regex zdaje się działać testowany w przeznaczonych do tego serwisach. Jednak w powyższym kodzie if zwraca false. O co chodzi?
@Matt23: match szuka od początku stringa (tak jakbyś dodał '^' na początek regeksa), search w całym stringu.
https://docs.python.org/2/library/re.html#re.match
https://docs.python.org/2/library/re.html#re.search
https://docs.python.org/2/library/re.html#re.match
https://docs.python.org/2/library/re.html#re.search
@zranoI: Dzięki!

#gmail #wyrazeniaregularne #internet #komputery
Słuchajcie mirki, potrzebuje takie wyrażenie regularne w gmailu
.@domena.pl
Niestety kropka odpowiada za jedną dowolną literę. W jaki sposób można ją przedstawić?
Słuchajcie mirki, potrzebuje takie wyrażenie regularne w gmailu
.@domena.pl
Niestety kropka odpowiada za jedną dowolną literę. W jaki sposób można ją przedstawić?


#wyrazeniaregularne #regexp #programowanie
Potrzebuję kilkunastu dobrze sprawdzonych wyrażeń regularnych (np. do walidacji formularzy tzn. np. z datą, godziną, emailem, numerem telefonu itd. itd).
Mógłbym sam je napisać, ale nie będą idealne. Mógłbym poszukać forach/stackoverflow, ale też nie jest pewne, że nie zawierają jakiś błędów.
Najchętniej wziąłbym z jakiegoś gotowca napisanego przez profesjonalistów. Wiem, że np. w C# (ASP.NET) są zaszyte gotowe do sprawdzania, podobnie jest chyba
Potrzebuję kilkunastu dobrze sprawdzonych wyrażeń regularnych (np. do walidacji formularzy tzn. np. z datą, godziną, emailem, numerem telefonu itd. itd).
Mógłbym sam je napisać, ale nie będą idealne. Mógłbym poszukać forach/stackoverflow, ale też nie jest pewne, że nie zawierają jakiś błędów.
Najchętniej wziąłbym z jakiegoś gotowca napisanego przez profesjonalistów. Wiem, że np. w C# (ASP.NET) są zaszyte gotowe do sprawdzania, podobnie jest chyba

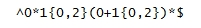{kind=link}
{kind=link}
No i np. dla emaila coś jest: https://github.com/hibernate/hibernate-validator/blob/6ae19900e2951513034534f9aec786689da9b4d8/engine/src/test/java/org/hibernate/validator/test/internal/engine/methodvalidation/returnvaluevalidation/ContactBean.java
@mk321: To jest faktycznie „tylko” test czy walidacja działa poprawnie.
Tu masz „constrainty”, czyli „definicje” co należy zwalidować, np możesz jakieś pole obiektu oznaczyć „constraintem”
URL, dzięki czemu system walidacji wie, że ma sprawdzić, że pole@MacDada: o to mi chodziło :) Dzięki :)
Właśnie nie mogłem znaleźć tych klas "walidatorów".
Teraz widzę, że od środka wygląda to trochę inaczej niż myślałem, i raczej mniej niż więcej jest oparte na wyrażeniach regularnych (no i jednak nie mogę ich tak
Właśnie nie mogłem znaleźć tych klas "walidatorów".
Teraz widzę, że od środka wygląda to trochę inaczej niż myślałem, i raczej mniej niż więcej jest oparte na wyrażeniach regularnych (no i jednak nie mogę ich tak
Druga część pytania - czy jeśli już mam regex który szuka dwóch wyrazów, to czy możliwe jest stworzenie takiego wyrażenia, które je pogrupuje tak, że w jednej grupie będzie dany string i liczba która się pojawia po nim (nie bezpośrednio) i w drugiej grupie to samo tylko z drugim stringiem i drugą liczbą?
Z której strony ugryźć ten temat? Gdzie
import re>>> a = "adam mial 23 lata, natomiast ewa miala dopiero 17 lat, kiedy się poznali">>> b = '(adam|ewa)[\D]+([\d]+)'>>> print(re.findall(b, a))[('adam', '23'), ('ewa', '17')]
A tak poważniej. Jako wprowadzenie bardzo spoko jest ten tutorial:
https://regexone.com
Bo automatycznie możesz sobie ćwiczyć przy nim.
Jak chcesz sobie ćwiczyć samodzielnie to polecam