Wszystko
Najnowsze
Archiwum

#scrapy #python #programowanie
siema. nie wiem gdzie robię błąd. To nie pierwszy crawler jakiego piszę ale miałem długą przerwę i gdzieś daję ciała.
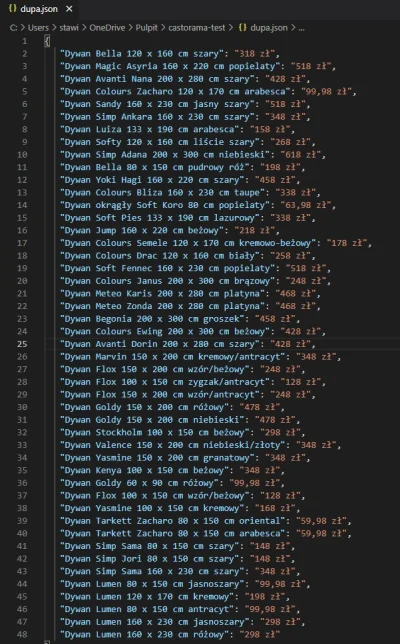
chcę ściągnąć ceny z castroramy. Dla przykładu niech będą to dywany. Korzystając z biblioteki #scrapy zadaję takie pytanie:
siema. nie wiem gdzie robię błąd. To nie pierwszy crawler jakiego piszę ale miałem długą przerwę i gdzieś daję ciała.
chcę ściągnąć ceny z castroramy. Dla przykładu niech będą to dywany. Korzystając z biblioteki #scrapy zadaję takie pytanie:
response.xpath('//span[contains(@class,
źródło: comment_1636835231e29yHol9ahlIgnlpX5VkFm.jpg
Pobierz@koku: selenium wypluł co trzeba
źródło: comment_1636840337A6a62GrdkqagpsPN5O1F6e.jpg
Pobierz
@koku: Na cholere to scrapować jak pod spodem to gada jsonem
https://www.castorama.pl/bold_all/data/getProductPriceStockByStore/?isAjax=true&store=1&typeBlock=recommended&needData=1144428,1144427,1144426,1144425,1144424,1144423,1108705,1108702,1107172,1098690,1098684,1098683,1098682,1055998,1055997,1055995,1055994,1055982,1055971,1055970,1029408,1021517,1015206,1005872,1005398,87198,86963,86961,86957,86956,86955,86954,86953,86952,86950,86948,46123
https://www.castorama.pl/bold_all/data/getProductPriceStockByStore/?isAjax=true&store=1&typeBlock=recommended&needData=1144428,1144427,1144426,1144425,1144424,1144423,1108705,1108702,1107172,1098690,1098684,1098683,1098682,1055998,1055997,1055995,1055994,1055982,1055971,1055970,1029408,1021517,1015206,1005872,1005398,87198,86963,86961,86957,86956,86955,86954,86953,86952,86950,86948,46123
ze mam przeczucie jakbym w kazdej chwili mial dostac bana
@kacper2006pl: to jest najgorsze w scrapowaniu publicznych stron, też zawsze sie tego obawiam xD
Hej, zacząłem się uczyć python i z ciekawości odskoczyłem na chwilę i zacząłem robić poniższy tutorial: https://analityk.edu.pl/web-scraping-z-uzyciem-biblioteki-scrapy-w-pythonie/. Problem pojawia się przy ostatniej komendzie:
scrapy crawl truecar -o truecar.csv - terminal zwraca mi, że nie ma takiej komendy, sprawdzając internet wyczytałem, że muszę być w jakimś odpowiednim miejscu w moim projekcie w pycharm, żeby komenda była dostępna, jednak kompletnie nie wiem co zrobić. Ktoś poratuje i wytłumaczy jak noobkowi? :) Jescze jak w@Henryhenry: dzięki za odpowiedź, tak muszę jeszcze doczytać na spokojnie o tych wirtualnych środowiskach i wielu innych rzeczach, próg wejścia jest dość spory hah :) póki co wieczorem spróbuję wybrać sobie inną stronkę do testów bo wybrałem chyba zbyt skomplikowaną i przetestuje spidera na czymś prostym jak te stronki z tutoriali czy w ogóle dziala.
@Tomz: spoko. To prawda, ale z każdym tutorialem i projektem akumuluje się całkiem sporo wiedzy i potem wszystko się pięknie w całość układa :) Co do tutoriali, to jeśli dopiero zaczynasz to warto najpierw robić kropka w kropkę tak jak jak w artykułach i dopiero potem powtarzać ze zmienionymi danymi. Z tego co piszesz wynika że problem nie leży w złożoności strony którą scrapujesz, tylko z samym użyciem narzędzia -
Treść przeznaczona dla osób powyżej 18 roku życia...

Komentarz usunięty przez autora

Mirki ma ktoś scrappera do olx pobierającego cenę i powierzchnię mieszkania, albo chciałby zrobić lub pomóc mi zrobić? (Ogarnę na tyle że ściągnę te dane z linku z ogłoszeniem, ale nie ogarnę jak zrobić to tak by 'wbijalo' na każde ogłoszenie i stamtąd ściągało dane. )
#programowanie #scraping #python #scrapy #webdev
#programowanie #scraping #python #scrapy #webdev

@AldoAldo: Tylko jeżeli nie masz doświadczenia, to poczytaj o tym jak uchronić się przed banem. Na jednych warsztatach uczyłem grupę 10 osób scrapowania serwisu aukcyjnego i następnego dnia cały budynek miał na niego bana xd
#programowanie #python #scrapy
kruci ma ktoś pomysł co zrobić z 405 przy logowaniu przez scrapy? próbowałem zmianę user agenta na coś mniej podejrzanego ale nie pomogło ;//
kruci ma ktoś pomysł co zrobić z 405 przy logowaniu przez scrapy? próbowałem zmianę user agenta na coś mniej podejrzanego ale nie pomogło ;//
@dog_meat:
"
The 405 (Method Not Allowed) status code indicates that the method
received in the request-line is known by the origin server but not
supported by the
"
The 405 (Method Not Allowed) status code indicates that the method
received in the request-line is known by the origin server but not
supported by the

@waldenstrom: to, co zacytowałeś, to dokładnie to, o czym pisałeś. Czyli metoda (czasownik HTTP, czyli np GET albo POST) , którą wysłałeś w zapytaniu nie jest obsługiwana dla danego zasobu (endpointu)

Dzisiaj Learning Scrapy
https://www.packtpub.com/packt/offers/free-learning
#packtpubfreelearning #python #scrapy
https://www.packtpub.com/packt/offers/free-learning
#packtpubfreelearning #python #scrapy

źródło: comment_YXhDjEjxYKc0GX5jcT8SbLGEZpxolgZa.jpg
Pobierz

Treść przeznaczona dla osób powyżej 18 roku życia...


Podczas ładowania strony przez skryp, mam cały czas kod odpowiedzi 404, albo 409. Ładuje przez proxy, ale nie wiem czemu niechce działać.
W przeglądarce odpalam przez proxy działa, a przez skrpyt nie...
Ustawiłem http_proxy na serwer docelowy i dalej nic..
Ma
W przeglądarce odpalam przez proxy działa, a przez skrpyt nie...
Ustawiłem http_proxy na serwer docelowy i dalej nic..
Ma

{kind=link}
{kind=link}
{kind=link}
Nie wiem czemu, ale chyba yield w #python `e mi nie dziala? :( pisze sobie crawlera w #scrapy, chce aby przeszukał jedna strone zebrał informacje które generują mi nowy linki do stron:
http://pastebin.com/LqxqbC42
A w konsoli wyskakuje takie coś:
http://pastebin.com/LqxqbC42
A w konsoli wyskakuje takie coś:
Tutaj jeszcze staty scrapiego powinien na conajmniej 10k stron wejsc a zatrzymuje sie na drugiej:
2016-06-03 12:02:51 [scrapy] INFO: Dumping Scrapy stats:
{'downloader/requestbytes': 232,
'downloader/requestcount': 1,
2016-06-03 12:02:51 [scrapy] INFO: Dumping Scrapy stats:
{'downloader/requestbytes': 232,
'downloader/requestcount': 1,
Zrobiłeem do scrapy.Request musiałem dodać
dont_filter=True
Dziekuje za nakierowanie mnie na rozwiązanie mojego ostatniego problemu :)
Niestety mam kolejne pytanie - w jaki sposób mogę wyłączyć javascript na stronie używając selenium?
Myślałem
https://stackoverflow.com/questions/59954995/how-to-install-chrome-extension-using-selenium-python
Dam znać co udało się stworzyć ( ͡° ͜ʖ ͡°)