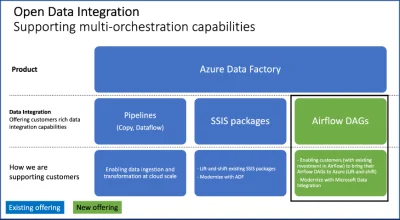
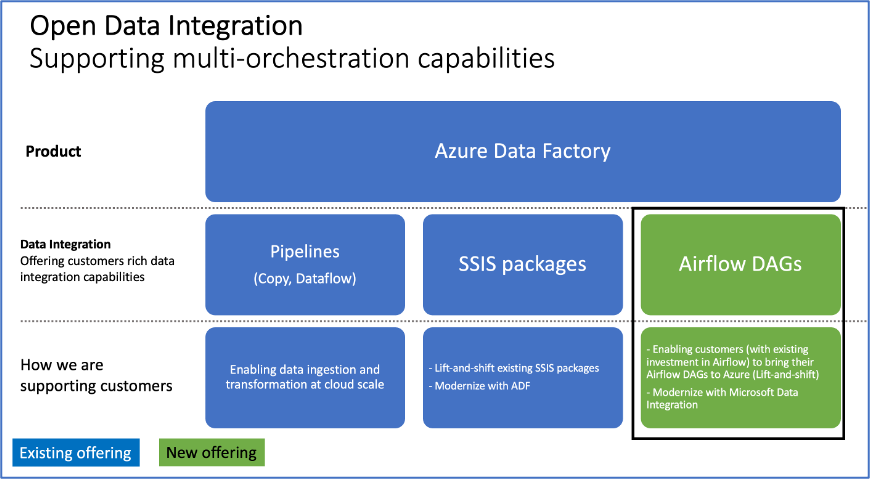
Microsoft chyba zrozumiał, że jego narzędzie do ETL/ELT/orchestration w cloudzie jest takie se i brakuje mu wielu przydatnych usprawnień. Więc po prostu dodał Airflow do niego xD Też fajnie. W sumie po co konkurować z open sourcami, skoro można je zaimplementować i skosić za to kasę od przedsiębiorstw.
https://techcommunity.microsoft.com/t5/azure-data-factory-blog/introducing-managed-airflow-in-azure-data-factory/ba-p/3730151
#apacheairflow #airflow #etl #businessintelligence #azuredatafactory #azure
https://techcommunity.microsoft.com/t5/azure-data-factory-blog/introducing-managed-airflow-in-azure-data-factory/ba-p/3730151
#apacheairflow #airflow #etl #businessintelligence #azuredatafactory #azure


{kind=link}
Poznaję to dopiero i rozkminiam. Obecnie mam zastany jeden ogromny notebook i kilka średnich i myślę czy tego nie porozdzielać na kilkanaście małych i potem to ładować do pipelinów.
#azure #azuredatafactory #synapseanalytics #azuresynapse #powerbi