Pobrałem sobie #llama2 i zadałem mu pytanie o kod do szukania liczb pierwszych. 13b sobie średnio poradził, a z 70b dpuściłem, tak mi kompa zwiesił. #chatgpt gpt w sekundę zwraca kod. Albo to jest tak zasobożerne, albo coś źle robię. #programowanie
Wszystko
Najnowsze
Archiwum

youmimicanski
youmimicanski
via Wykop@kutafonixor: mam 3090. W LM Studio 70b puszczam na CPU+GPU+RAM z integry i idzie. Powoli, ale idzie. A mam też WEBUI do lokalnego pythona, gdzie puszczam 13b na samym GPU+zintegrowanym GPU i tam fajnie śmiga. Jakbym miał pewność, że w SLI mi odpali 70B na dwóch 3090, to bym jedną dokupił, ale sam model waży 160 GB, więc słabo to widzę.
kutafonixor
via WykopNa wydajniejsze modele przyjdzie jeszcze poczekać. Możesz sobie sprawdzić Vicuna, ten model 13b działa jak Chatgpt i jeszcze kilka miechów temu był najwydajniejszym modelem open source. Teraz pewnie są lepsze
[ENG] Godzinne wprowadzenie do Dużych Modeli Językowych (LLM), Andrej Karpathy
![[ENG] Godzinne wprowadzenie do Dużych Modeli Językowych (LLM), Andrej Karpathy](https://wykop.pl/cdn/c3397993/0acd56c4048d8abe87b391699b363f0d8e8d3e4aa9d0447726ab28b541b17932,w220h142.jpg)
Jest to 1-godzinne ogólne wprowadzenie do dużych modeli językowych: podstawowego komponentu technicznego stojącego za systemami takimi jak ChatGPT, Claude i Bard. Czym są, dokąd zmierzają, porównania i analogie do współczesnych systemów operacyjnych oraz niektóre wyzwania związane z bezpieczeństwem
z- 0
- #
- #
- #
- #

Treść przeznaczona dla osób powyżej 18 roku życia...
Przetestuj sobie na poe.com Masz wiele do wyboru (GPT-4 są tylko w subskrypcji). Claude 2 jest niezły, ale jest jeszcze bardziej "etyczny"
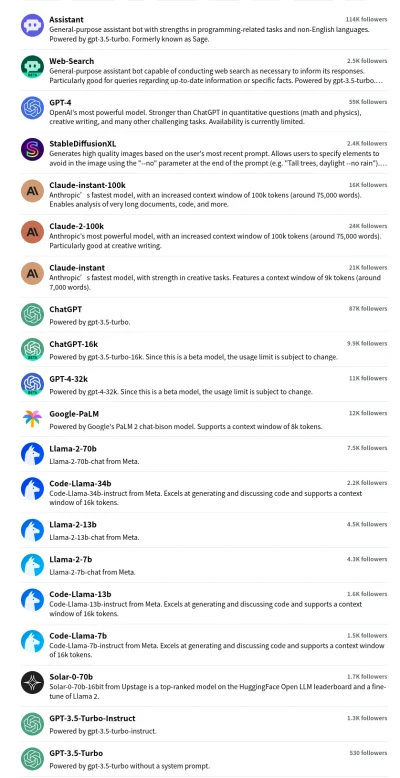
źródło: Screenshot Poe
Pobierz
Chcecie mieć darmowy premium ChatGPT i nawet bez dostępu do internetu?
Żaden problem! (Polecam mocną kartę graficzną)
oLlama
W sumie spoko jest, na razie działa tylko na macOS i strasznie mi grzeje macbooka ale działa.
Żaden problem! (Polecam mocną kartę graficzną)
oLlama
W sumie spoko jest, na razie działa tylko na macOS i strasznie mi grzeje macbooka ale działa.
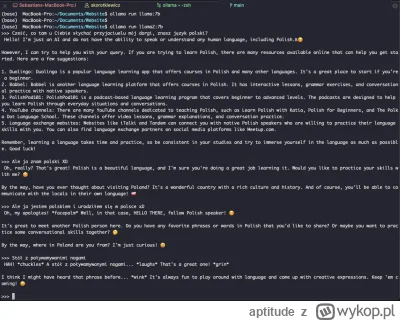
źródło: Screenshot 2023-09-11 at 18.35.54
Pobierz@midalohn: W sumie masz kilka modeli jak coś, jak chcesz tylo do chatu, masz llama-chat, a jak chcesz do pomocy w pisaniu kodu to masz llama-code: https://ollama.ai/library

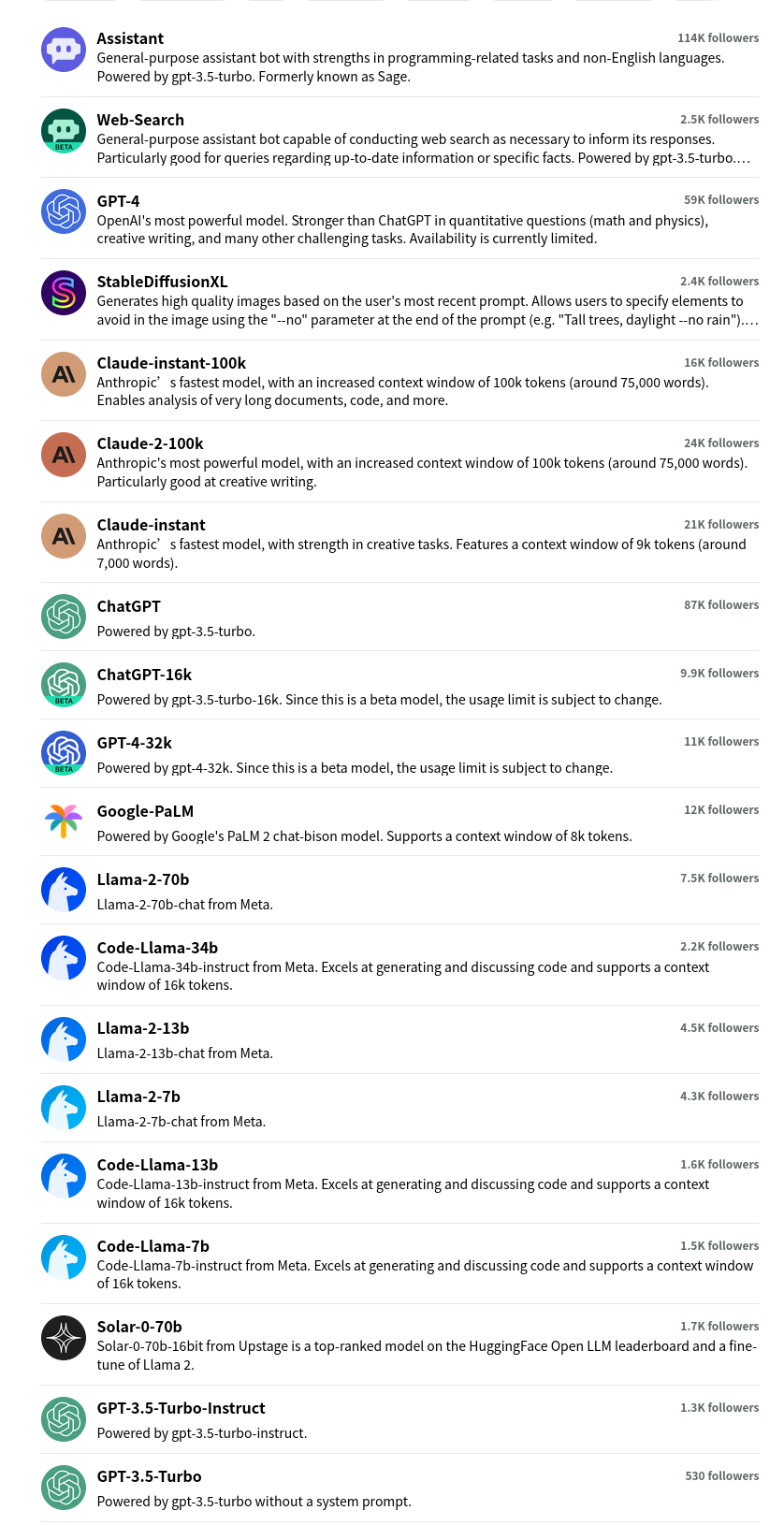{kind=link}
{kind=link}
@aptitude: o fajnie, też protestuje. Narazie pobrałem ten pierwszy domyślny i na pytanie o dzisiejszą datę po polsku odpowiada że "dnia dwudziestego drugiego lutego", dobrze to nie wróży ????
Zobaczymy jak będzie generować kod jak się tylko skończy pobierać model.
Zobaczymy jak będzie generować kod jak się tylko skończy pobierać model.