Jako laik zastanawiam się jakie są różnice pomiędzy #selenium a #beautifulsoup. Oba są do tego samego, ale czy któryś jest np. latwiejszy, bardziej rozbudowany itd? Mam zamiar napisać program który będzie monitorował ceny konkretnych produktów w sellgrosie a następnie wysyłał maila pod wskazany adres jeśli cena będzie mniejsza niż x. Z jakiego modułu byście skorzystali i dlaczego? Pozdrawiam #python
Wszystko
Najnowsze
Archiwum

kwiato
via iOS
arysto2011
@kwiato: selenium symuluje przegladarke i wymaga drivera do dzialania. BS to parser HTML.

trzy_razy_rzezucha
@kwiato: jeżeli potrzebne dane są wysyłane zwykłym html to bf4 wystarczy, jak jest javascript który musi coś policzyć lub przerobić to wtedy selenium

#python #beautifulsoup
Próbuję łapać cenę randomowego produktu na amazonie i program działa..., a czasami nie działa. Wywala błąd:
title = soup.find(id='productTitle').gettext()
AttributeError: 'NoneType' object has no attribute
Próbuję łapać cenę randomowego produktu na amazonie i program działa..., a czasami nie działa. Wywala błąd:
title = soup.find(id='productTitle').gettext()
AttributeError: 'NoneType' object has no attribute

@boguslaw-de-cubalibre: dodaj sobie obsługę wyjątku, żeby przy wystąpieniu błędu zapisywało treść strony i wtedy będziesz mógł sprawdzić, czy serwer zwraca to, czego oczekujesz

@boguslaw-de-cubalibre: na przyszłość kod w pastebina wrzucaj, będzie czytelniejszy.
Generalnie, błąd wyskakuje przez to, że find() zwraca wartość NoneType, bo nic nie może znaleźć.
Odpaliłem ten kod no i ogólnie to wygląda tak jakby nie każdy request zdążył załadować wszystkie elementy strony. Odpaliłem ten sam skrypt, tylko przerobiłem go tak by źródło strony pobierał przy pomocy Selenium - tytuł i cenę zwraca za każdym wykonaniem pętli.
Z tego co się orientuje, jak strona
Generalnie, błąd wyskakuje przez to, że find() zwraca wartość NoneType, bo nic nie może znaleźć.
Odpaliłem ten kod no i ogólnie to wygląda tak jakby nie każdy request zdążył załadować wszystkie elementy strony. Odpaliłem ten sam skrypt, tylko przerobiłem go tak by źródło strony pobierał przy pomocy Selenium - tytuł i cenę zwraca za każdym wykonaniem pętli.
Z tego co się orientuje, jak strona

#programowanie #python #scraping #beautifulsoup
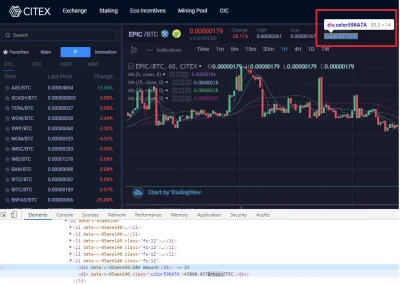
Siemka, jest sprawa - dobiłem do ściany i potrzebuję żeby ktoś wskazał kierunek :/.
SEDNO: oglądam tutoriale i próbuję nauczyć się przy pomocy pythona i bs4/ scrapy zebrać dane z giełdy kryptowalut i za cholerę nie umiem - poradniki zawsze omawiają na bazie stosunkowo prostych stron i z tym nie mam problemu, ale jak przychodzi do real-life zazwyczaj dostaję [ ]...
MORE:
Siemka, jest sprawa - dobiłem do ściany i potrzebuję żeby ktoś wskazał kierunek :/.
SEDNO: oglądam tutoriale i próbuję nauczyć się przy pomocy pythona i bs4/ scrapy zebrać dane z giełdy kryptowalut i za cholerę nie umiem - poradniki zawsze omawiają na bazie stosunkowo prostych stron i z tym nie mam problemu, ale jak przychodzi do real-life zazwyczaj dostaję [ ]...
MORE:
źródło: comment_1582725862QtVZWBB3n26MO0YYg5XFRY.jpg
Pobierz
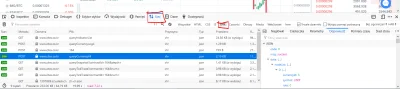
@blacktyg3r: używasz selenium? Bo problem pewnie jest przez treść renderowaną w js. Zresztą spójrz lepiej w zakładkę network, wszystkie dane są pobierane requestami z api z tego co widzę.
@blacktyg3r: skupiłbym się raczej na drugiej części tamtej odpowiedzi. ( ͡° ͜ʖ ͡°)
Strona o której mówisz ma pod spodem api. Dokumentacji może nie mieć, po prostu spójrz jakie requesty robi twoja przeglądarka jak otwierasz stronę i powtórz je w pythonie. Dostaniesz ładnego JSONa z danymi.
Strona o której mówisz ma pod spodem api. Dokumentacji może nie mieć, po prostu spójrz jakie requesty robi twoja przeglądarka jak otwierasz stronę i powtórz je w pythonie. Dostaniesz ładnego JSONa z danymi.
źródło: comment_1582731300ZiiO6Ky2nBtGgofqmijNyP.jpg
Pobierz
Hejka,uczę się pisania web crawlerów i mam problem z #beautifulsoup, a dokładnie z tym by zaciągnąć większą ilość danych gdy są one na stronie pobierane w tle (ajax?) tak jak w przypadku wykopu.
Gdy zaciągam źródło strony ładowane jest 50 pierwszych znalezisk dla danego tagu,więcej ładuje się po zescrollowaniu strony.
Co zrobić żeby załadować więcej znalezisk ? Do pobrania zawartości używam freamworka #requests
krótki kod tego co nabazgrałem: https://pastebin.pl/view/1677c573
bądźcie wyrozumiali,
Gdy zaciągam źródło strony ładowane jest 50 pierwszych znalezisk dla danego tagu,więcej ładuje się po zescrollowaniu strony.
Co zrobić żeby załadować więcej znalezisk ? Do pobrania zawartości używam freamworka #requests
krótki kod tego co nabazgrałem: https://pastebin.pl/view/1677c573
bądźcie wyrozumiali,
@malostkowy: jeśli to jakiś ajax to możesz użyć selenium. Jeśli tylko adres się zmienia, tak jak na wykopie, czyli wykop.pl/strona/2 to w pętli for podawaj kolejne adresy strony 2/3/4 itd

@malostkowy: takie strony raczej mają sitemap.xml

Potrzebuje pobrać dane ze strony gwp (https://www.gpw.pl/kontrakty_terminowe_pelna_wersja ), interesują mnie wartości z wskaźnikami z tabeli class="tab03 tabFloatingHeader"
gdy próbuje się pobrać przez:
gdy próbuje się pobrać przez:
r = requests.get(url)
soup = BeautifulSoup(r.content,
@seelk: Tu są: https://www.gpw.pl/ajaxindex.php?action=GPWQuotations&start=showDerivativesTable&tab=ipk_indeksy&type=K⟨=PL⌖pagecard=&defaultorder=cval&full=1

Robię prosty scrapper, który wyciąga linki ze stron www. Natknąłem się na 2 strony, których budowa jest dosyć nietypowa przez co nie mogę dobrać się do linków. Te strony to:
http://www.wp.pl/ - nie ma w swojej strukturze żadnych linków - widać to w źródle strony.
http://docs.celeryproject.org/ - przekierowuje do http://docs.celeryproject.org/en/latest/ co jest rozsądne ale jak zrobić uniwersalną regułę, która będzie przygotowana na takie sytuacje? Jak pobrać docelowy adres?
Czy
http://www.wp.pl/ - nie ma w swojej strukturze żadnych linków - widać to w źródle strony.
http://docs.celeryproject.org/ - przekierowuje do http://docs.celeryproject.org/en/latest/ co jest rozsądne ale jak zrobić uniwersalną regułę, która będzie przygotowana na takie sytuacje? Jak pobrać docelowy adres?
Czy

{kind=link}
{kind=link}
http://www.wp.pl/ - nie ma w swojej strukturze żadnych linków - widać to w źródle strony.
@soma115:
* a.) Musisz mieć bajer, co ogarnia JSa: http://phantomjs.org/
* b.) Jest wersja z
Czy możesz mi podać jakieś przykłady 'pobieraczy'?
@soma115: http://docs.guzzlephp.org/en/latest/request-options.html#allow-redirects
Czy BeautifulSoup to