Aktywne Wpisy
BoroPrimorac +237
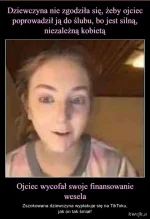
Pamiętacie tę żenadę jak uśmiechnięte fajnopolaki z warszawki oglądali obrady sejmu w kinie?
#polska #wybory #sejm #warszawa #nieruchomosci
#polska #wybory #sejm #warszawa #nieruchomosci

źródło: Zdjęcie z biblioteki
Pobierz
kotka-a +200
źródło: 4DNJHjIZPRZXybJm
Pobierz



{kind=link}
{kind=link}
SELECTNumer,
(SELECT TOP 1 Wartosc FROM Tabela_B WHERE Tabela_B.Numer = Tabela_A.Numer ORDER BY ID DESC)
FROM Tabela_A
Czyli pobieram TOP 1 jakaś wartość z TabelaB wedle numeru z TabelaA, ale działa to wolno.
Jak to przyspieszyć?
#sql #mssql #programowanie #bazydanych
SELECT TOP 1 zmienić na joina do tabeli B i sprawdzić jak działa
Na przykład.
SELECTa.Numer,
b.Wartosc
FROM Tabela_A
LEFT JOIN (
SELECT
b.Numer,
b.Wartosc
FROM Tabela_B b
INNER JOIN (
SELECT
MAX(ID) AS id
FROM Tabela_B
GROUP BY Numer) bb
ON bb.ID = b.ID
) b
ON b.Numer = a.Numer
Indeks według zasady POC (Partitioning, Ordering, Covering)
coś takiego może?
SELECT A.Numer, X.Wartosc FROM TabelaA A
OUTER APPLY
(
SELECT TOP 1 Wartosc FROM TabelaB WHERE Tabela_B.Numer = A.Numer ORDER BY ID DESC
) X
nie wiem czy to cos usprawni
źródło: comment_1637844391eQyYgkQJ09ebE4kw7SpV1N.jpg
PobierzSprawdzałem i nie działa, w każdym wypadku podobnie a nawet i gorzej
Coś się zmieniło w planie po dodaniu indeksu co @DarkAlchemy i @nowy1333123123 podawali?
Wartosc to jakas kolumna czy wyrażenie liczone z czegoś?