Aktywne Wpisy

baton967 +48
nie moge się wysrać od jakichś 5 dniu xd mam w sobie tone gówna a dupa zaklejona na amen... wybuchne over żegnajcie
ps. sorrka za śmierdzący post
ps2. zaaplikowałem czopa #przegryw
ps. sorrka za śmierdzący post
ps2. zaaplikowałem czopa #przegryw

źródło: pobrane (3)
Pobierz
atrax15 +116
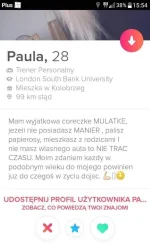
źródło: temp_file6917772698856058183
Pobierz




{kind=link}
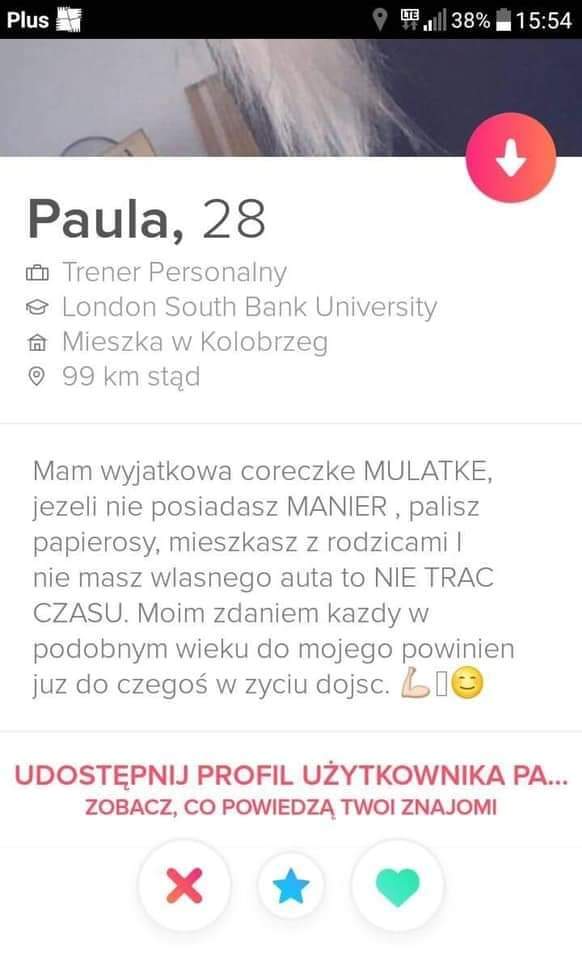{kind=link}
Patrząc na oferty to strasznie hermetyczna branża
#dataengineering
No i jak firma daje budżet szkoleniowy to żal nie zużyć ( ͡° ͜ʖ ͡°)
Znajomość Sparka oraz powiązanych zagadnień to jest
A ty które examy byś brał?
Tylko jedzcze jedna wada, te certy sa wazne tylko na rok (z innych vendorow jest zazwyczaj 2 minimum)
@cohontes: moja firma nie robi w ogóle w DE i używa co najwyżej ADF. Certy robię na przyszłość, bo wiem że wiecznie tu siedział nie będę