Aktywne Wpisy

LuckyStrike +33
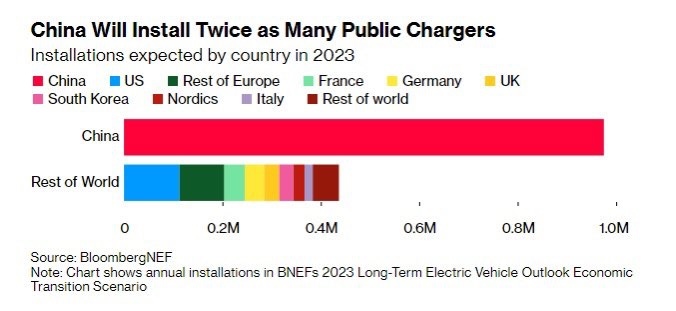
Tyle zainstaluje się publicznych ładowarek do samochodów w Chinach vs reszta świata xD
#motoryzacja #chiny #tosachiny
#motoryzacja #chiny #tosachiny
{kind=link}


Watchdog_Polska +302
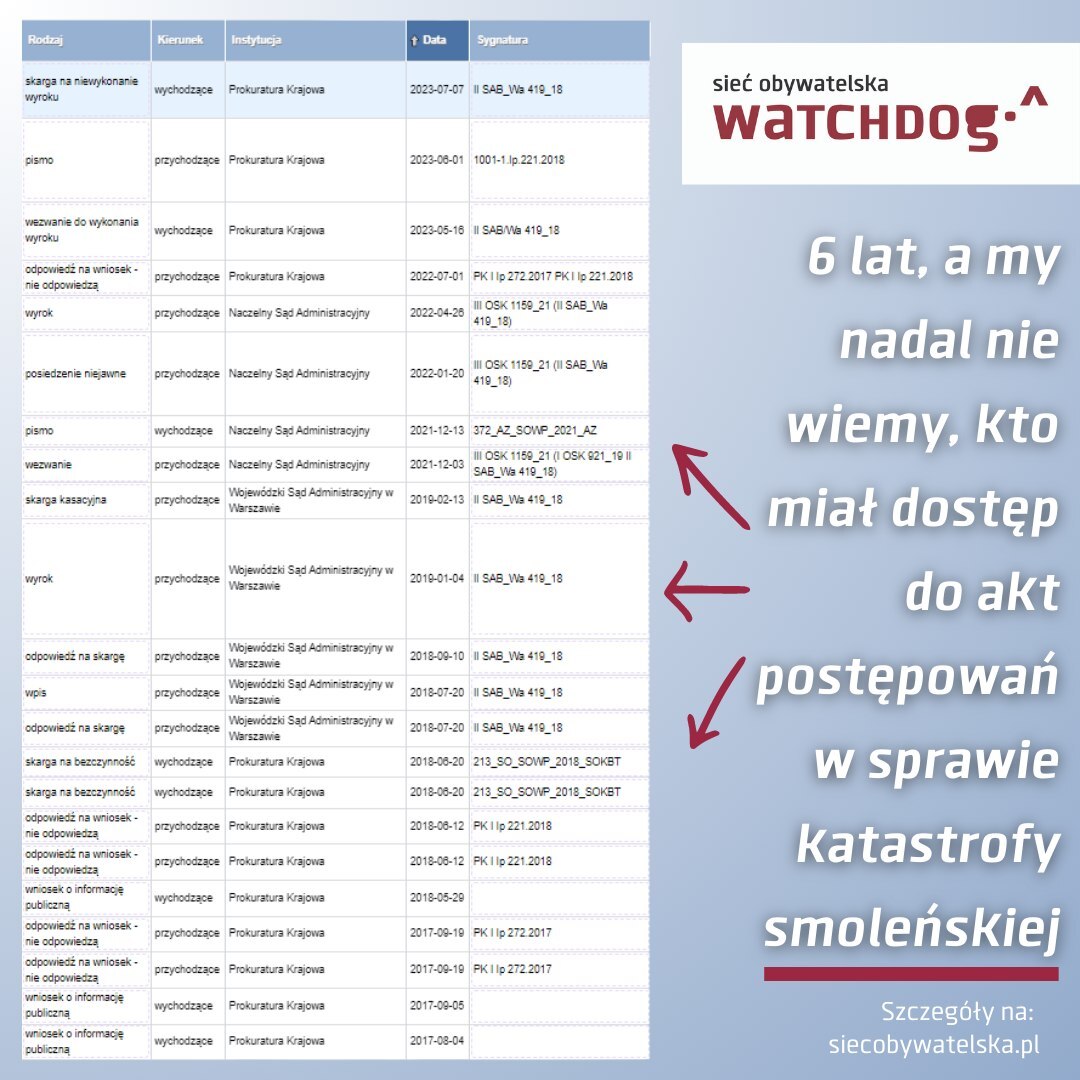
Od prawie 6 lat usiłujemy się dowiedzieć, kto miał dostęp do akt postępowań w sprawie katastrofy smoleńskiej. Najpierw odmawiano nam dostępu z powodu wciąż trwających postępowań, potem Prokuratura Krajowa uznała, że nasz wniosek jest nieprecyzyjny. Nie pomogły wyroki WSA i NSA, dlatego złożyliśmy skargę na niewykonanie wyroku. Więcej na ten temat na naszej www.
.
.
.
.
P.S. Od wczorajszego popołudnia wiadomo już, że wybory parlamentarne odbędą się 15 października.
.
.
.
.
P.S. Od wczorajszego popołudnia wiadomo już, że wybory parlamentarne odbędą się 15 października.
{kind=link}
Aktywne Znaleziska





#programowanie #python #bigdata
stringIOvsbuffor był doładowywany: o co chodzi? StringIO trzyma całość w pamięci, jaki sens ma doładowywanie czegokolwiek?To może Ci się przydać. Z rok temu musiałem ostro ładować postgresa i może i w pythonie szybko się kodowało, ale za to trwało to wieczność.
Z tym pgbulkinsertem ładowałem po milion rekordów w niecałą minutę z tego co pamiętam.