
Poszukuję kontaktu do specjalisty od PANDAS dla dziecka.
Ktoś coś? Szukam lekarza specjalistę a nie wypisywacza recept i zwolnień.
W USA wystarczy że wpisze miasto i są adresy specjalistycznych przychodni od PANDAS.. ale w PL zero nie ma nic i nikogo ;/
#pandas #choroby #lekarze #pytanie #zdrowie #medycyna #leki #leczenie
Ktoś coś? Szukam lekarza specjalistę a nie wypisywacza recept i zwolnień.
W USA wystarczy że wpisze miasto i są adresy specjalistycznych przychodni od PANDAS.. ale w PL zero nie ma nic i nikogo ;/
#pandas #choroby #lekarze #pytanie #zdrowie #medycyna #leki #leczenie






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
6:30
dlaczego
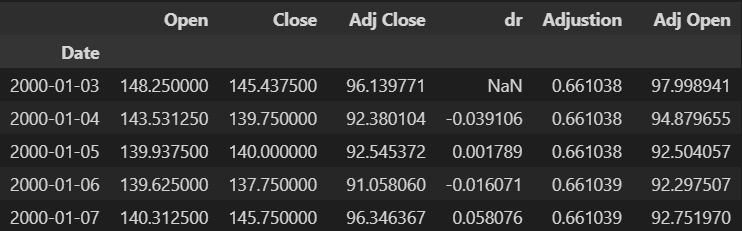
Zwraca 6 kolumn? Wiem, że indexowanie od 0.
Ale czemu w takim razie nie wpisze 0:5 ? Skąd 10 tam?
#python #pandas #programowanie